

Comparing Static and Runtime Reachability
Comparing Static and Runtime Reachability
Revealing the pros and cons of two emerging types of reachability


In our last article, we established the goal of reachability, namely determining the exploitability of a CVE in the context of our application. In the third article, we’ll talk about how complicated this actually gets, but first, the marketplace has given us two primary methods for achieving reachability: static and runtime reachability. Each of these methodologies has two subcategories: package level and function level reachability. Despite vendor’s convictions around their chosen methods, static and runtime reachability each have real pros and cons, which is why there are many providers offering one or the other, but not usually doing both.
In this article we’ll explain the differences between static and runtime reachability, package and function level reachability, and enumerate the pros and cons of each. In the next article, we’ll dissect types of runtime reachability, and see how complicated the problem really gets.
Prolegomena
First, we need to set the record straight on reachability more broadly: it’s currently a maturity mess. Here are just a few brief things to keep in mind when assessing the reachability of specific tools:
Tying exploitable functions to CVEs is a proprietary process. Some vendors are using AI for it, others are doing it by hand. Some have been doing it for years, some for months. Some are baselining function behavior, others are baselining packages or images. This is why mileage will vary and it’s very language dependent.
The main functionality difference among reachability vendors is if it extends to the function level. For example, Sysdig has had “loaded or not loaded” for years, but this hasn’t changed the industry in the way function level does. Both the false positive rate is too high, and response aspects too limited.
Some tools are even combining reachability telemetry from tools, combining runtime vendors and static vendors to bring another layer of prioritization out of the sea of data. These tend to be more on the vulnerability management side, so we won’t address them as much here.
Static Reachability
My first exposure to function level static reachability was from Endor Labs, and has been prominently extended into SAST by BackSlash, who is also focusing on reachability from a user input perspective. Since their launches however, “reachability” has become a checkbox feature for almost every major SCA provider - everyone says they have it, but it’s really hard to tell what they mean. In order to understand the mess the market has made from this, let’s differentiate first between package level and function level static reachability with an example.
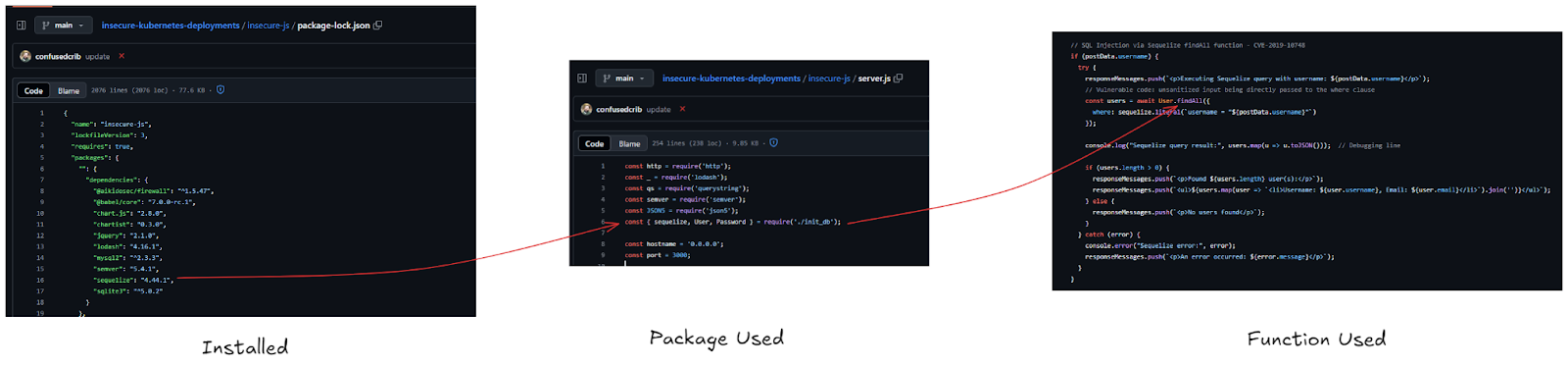
In this code example, I import sequelize via my package.json, I then use the library in my code, and then I use a specific exploitable function from that library. Let’s think about what this does from a vulnerability prioritization perspective. I import 10 libraries, but there’s only 1 real vulnerability:
No Reachability: In my package.json, I import 10 libraries, which in turn import a bunch of transitive dependencies with them. This leads to a vulnerability count of about 400.
Package Level Reachability: Of all these libraries I import, I only actually use about half of them, the rest are leftovers from testing or old projects. In real world environments, you probably use most of the libraries you’re importing, but package reachability will tune out some of the noise here, just not much of it. On a good day, this reduces the vulnerability count to around 100.
Function Level Reachability: This is detecting that the `findall` function in sequelize is the one with the actual vulnerability. This is telling me it’s actually exploitable and brings my total vulnerability count down to 4.
It’s also worth briefly mentioning the other kinds of static reachability that are out there: some vendors define it by public code repos, others tie it to the code to cloud picture; however, this is why I stick with the definition of reachability where it’s related to discovering truly exploitable code, those other definitions don’t really help with that.
Pros of Static Reachability
In my opinion, function level reachability is the most significant differentiator in the static SCA space because it consistently brings a 90-99% reduction in total vulnerability counts. SCA scanners are synonymous with high false positive counts, and function level reachability does an admirable job trying to bring those numbers down 90% or more. This level of reachability seems like the most that’s possible to do from purely looking at the code, because it functions more like a SAST scanner, exploring application paths to find exploitable code. When combined with BackSlash’s approach of looking for user input, the possibilities further reduce false positives.
Usually, SCA scanners integrate based on connecting into your source code library. This makes them easy to integrate, and you can start getting results immediately. Traditionally, this is why SCA scanners continue to be the starting point for many application security programs - they give the feeling of a ton of visibility, within minutes of connecting a code repo.
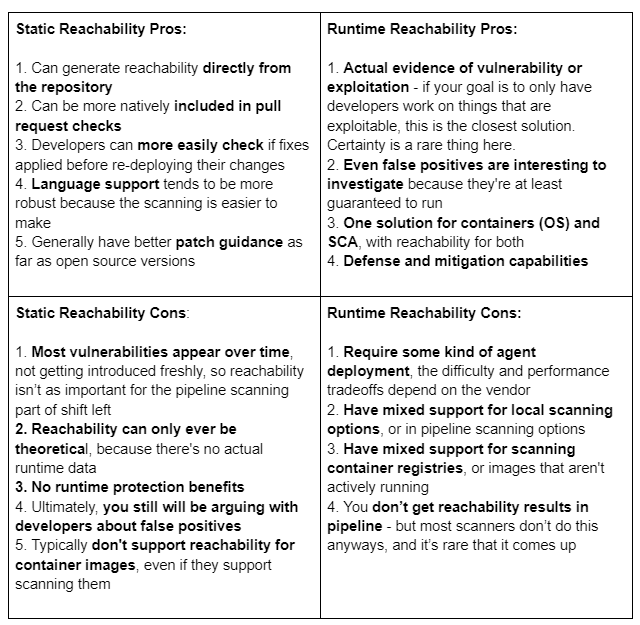
Static Reachability Pros:
1. Can generate reachability directly from the repository
2. Can be more natively included in pull request checks
3. Developers can more easily check if fixes applied before re-deploying their changes
4. Language support tends to be more robust because the scanning is easier to make
5. Generally have better patch guidance as far as open source versions
Cons of Static Reachability
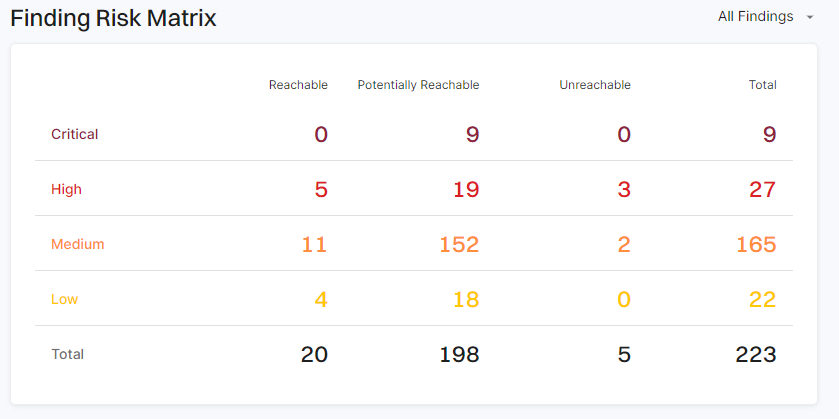
Certainty is a hard thing from static analysis! There are 4 actually exploitable vulnerabilities in this repo, but static scanning cannot know that.
SCA scanning without runtime context does have some major downsides. First, there are some issues with the concept of “shifting vulnerability scanning left” as a complete solution. Companies, myself included, have overvalued the idea of “stop the bleeding” and have largely abandoned blocking pipelines based on discovering new critical CVSS score vulnerabilities. The false positives are too high to justify, and the patching process too time consuming.
The hidden issue with static reachability is also scan time. While reachability reduces vulnerability counts, you pay a cost in increased scan times to get that additional data. Once again, the benefit here is not “shifting left” as much as getting noise reduction for a traditional vulnerability management workflow. Tools like Backslash do a great job here by running a quick scan on changes, but enhancing with reachability data over time.
Finally, if the idea of reachability is to “never waste a developer's time ever again,” static reachability simply cannot accomplish this high minded goal. Ultimately, the best function reachability in the world cannot see whether or not that piece of code is actually executing or not.
If you were to take the full context of my testing repository, I know that only 4 of those vulnerabilities actually execute once my application is deployed - but a static scanner doesn’t. That’s why scanning my repo with Endor Labs shows 20 vulnerabilities, and not only 4 like it should.
While it’s no small feat to get from 400 vulnerabilities down to 20, I think the next conversation will just be “how do we get from 12 to the actually exploitable 4?” and this is where static reachability cannot succeed on its own. No matter how good it gets, it can’t know what’s actually running or not.
Static Reachability Cons:
1. Most vulnerabilities appear over time, not getting introduced freshly, so reachability isn’t as important for the pipeline scanning part of shift left
2. Reachability can only ever be theoretical, because there's no actual runtime data
3. No runtime protection benefits
4. Ultimately, you still will be arguing with developers about false positives
5. Typically don't support reachability for container images, even if they support scanning them
Runtime Reachability
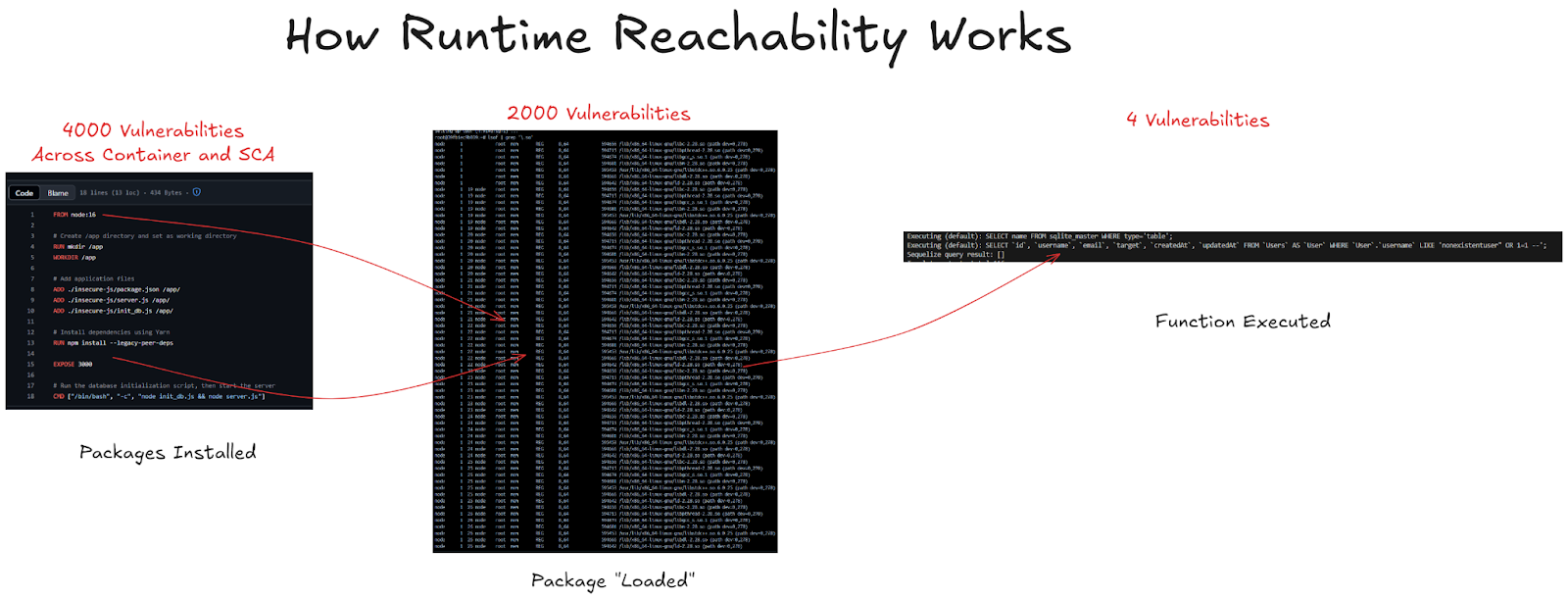
In one sense, runtime reachability has been around for a long time. Scanners like Sysdig or Aqua have shown which libraries “are loaded into memory” for years, and it’s now a common CNAPP feature. This package level reachability has the same marketing over functionality promise as it does with static reachability - you do indeed get some reduction, but it’s never that impactful.
Like with static package level reachability, the impacts here are mixed. There is a slight reduction in vulnerability counts, but it doesn’t really get at the heart of letting you know what’s exploitable or not. During a container’s lifecycle, a lot of packages may get loaded or unloaded for a variety of reasons, but this doesn’t really tell you about what an application is doing because it doesn’t have insights into the application layer of the workloads.
Function level reachability radically changes the impact of runtime reachability! This kind of data has been traditionally reserved only for difficult to implement RASP solutions, outside the scope of most security teams. There is a new wave of vendors that enable function level reachability with only an agent deploy, and it’s a cool enough new feature only four really do it: Raven.io, Oligo Security, Kodem, and Sweet Security. Of these, it’s worth mentioning that language and CVE support is all over the place in terms of maturity, and this is the single most quickly changing field in runtime cloud security.
Another important thing to know about this kind of scanning is that it works across both OS and Code library scanning. This is another advantage of the approach - as you’re essentially getting two kinds of scanning and reachability out of a single platform.
Pros of Runtime Reachability
There’s no other way for me to put this, but function level runtime reachability is mind blowing when you see it in action. In theory, I thought it would be over-rated. After all, static reachability reduces the vulnerability count to a similar number, but it does it earlier in the developer lifecycle. However, the thing I missed is how freeing it is to see only true positives - or at least interesting - vulnerabilities in your runtime environment.
I’ve become so accustomed to sifting through false positive vulnerability results, it’s an amazing experience to see function level details, letting you know that function with a vulnerability is executing in your environment. You can even use it to do meaningful investigation work, like taking the time to look at the environmental context of a workload alongside the function execution to know almost immediately if an exploit would be possible.
Part of this is why I’ve changed my definition of reachability from “showing a potentially exploitable vulnerability” to just “knowing an exploit is possible.” This is really the goal of reachability, and runtime function execution data can get you this holy grail - of knowing specifically that a vulnerability is running in your environment.
Furthermore, vendors in this category also do ADR - application detection response - enabling teams to either proactively or reactively protect against novel application layer exploitations. Raven.io and Oligo are the farthest ahead at taking these response actions against malicious payloads, stopping malicious function actions without breaking the application itself.
It’s also worth noting that these vendors also combine SCA and Container Vulnerability scanning results into a single place - so you’re getting code and container vulnerabilities, with the best reachability that’s out there, into a single system.
Runtime Reachability Pros:
1. Actual evidence of vulnerability or exploitation - if your goal is to only have developers work on things that are exploitable, this is the closest solution. Certainty is a rare thing here.
2. Even false positives are interesting to investigate because they're at least guaranteed to run
3. One solution for containers (OS) and SCA, with reachability for both
4. Defense and mitigation capabilities
Cons of Runtime Reachability
Despite being mind blowing in action, runtime reachability’s biggest weakness is that you need to get it into action in the first place by deploying an agent. However, this is why I especially like agent based approaches over traditional RASP vendors - they are easily deployed across Kubernetes clusters like any other helm chart. While that deployment process might involve other teams, the implementation is infinitely less time consuming than making code changes across all of your services, as well as deeper application changes..
The biggest negative is the mixed developer experiences from these vendors when it comes to scanning containers before they’re deployed. Some of them lack CLI’s for scanning, pipeline integrations, container registry scanning, pull request scanning, and the many traditional developer experience benefits of a “shift left” approach. This is why I think the future here is runtime telemetry feeding into an ASPM platform for complete code and runtime coverage.
Runtime Reachability Cons:
1. Require some kind of agent deployment, the difficulty and performance tradeoffs depend on the vendor
2. Have mixed support for local scanning options, or in pipeline scanning options
3. Have mixed support for scanning container registries, or images that aren't actively running
4. You don’t get reachability results in pipeline - but most scanners don’t do this anyways, and it’s rare that it comes up
Example: Pyyaml

Let’s look at a vulnerability in pyyaml that’s illustrative of many vulnerabilities. Based on this report of the original vulnerability, if an attacker can send a malicious yaml to the function that loads the data, they can also execute arbitrary code on the underlying system. As a result, this is marked as a high severity vulnerability.
An example reflective of your internal vulnerability discussions can be found on this Github issue about it, where someone requests the version to be bumped, and a discussion ensues about how realistic an attack actually is. On the one hand, the issue raiser is correct that it is slightly more secure for some edge cases to patch the version - such as publicly available CI systems. Conversely, the maintainers are also correct that if someone has the ability to send hand crafted yamls to your system, they already have a lot of permissions that this vulnerable software probably isn’t your biggest concern.
In this example, the key to understanding the exploitability of the vulnerability is the runtime context. Static reachability is close - it tells you whether or not the load yaml function is actually getting called. This is helpful for tuning out many obviously applicable or not applicable vulnerabilities. However, the solution can never tell you things like if the function is only executing in lower environments, in production, or the stack trace of calls that initiates it at runtime. Only runtime reachability hits the actual goal: knowing if you’re actually vulnerable or not.
Summary
If you’re like me, runtime reachability seemed like a gimmick at first. Unfortunately, the CNAPP vendors have the biggest marketing budget and are making this problem worse - they position runtime reachability as “eBPF plus loaded packages” and go “we have that!” However, function level runtime reachability opens a new world of possibilities in both vulnerability prioritization and runtime protection.
Static reachability has some real benefits - it’s a marginal improvement over the older scanning methods of just looking at package.lock files and spitting out the results. However, long scan times and mixed accuracy can muddy the benefits over time. To be clear, the developer experience is important here, so I by no means discount vendors in this category; however, there is simply nothing like the clarity that can come from modern ADR.
This is why in general I see the benefits of combining an ASPM + Runtime reachability approach. If the goal of reachability is detecting exploitability, runtime will always be the only place that can be accomplished with certainty. The main benefits of static reachability are more workflow oriented than the results themselves, which isn’t meant to discount the feature at all, as workflows are also incredibly important in this arena! However, if you’re looking for a guarantee to stop wasting any developer time at all - runtime function level reachability holds the answer.
Between static and runtime reachability, the one I recommend, like most things, comes down to goals and use cases. If you want the best detection, prioritization, and prevention you can get, and don’t mind installing an agent, I’d recommend runtime. If you want the easiest possible way to check the dependency scanning box, or just want a better version of your existing SCA scanner, I’d recommend static.
This post is meant to be educational and was completed in collaboration with the team at Raven.io. This is not meant to be a product endorsement or review.
I think the agent requirement (even if eBPF plug-in only) is a big hill for a startup. It would have to be part of a multi-faceted agent (e.g. Sysdig or Falcon). Alternatively, these vendors could be inspired of DAST scanning techniques to simulate runtime execution pre-deployment?...
Amazing read 👍 informative.