

AI Code Security: Enterprise Governance for AI Generated Code
How AI is changing the code security process

AI code generating agents like Claude Code and Codex have changed how code is written, unlocking new opportunities and risks for businesses. Security teams are currently investing in two different areas: securing AI generated code and security for AI agents across their workforce. Most tools specialize in one or the other, with application security oriented tools focusing on secure code generation, and AI security tools focusing on securing agents themselves.
Over the next few years, several existing and emerging application security capabilities will converge into a single category: AI Code Security. This new category will be designed by a set of technologies that will define the future of application security.
This category is future-oriented: no single vendor does all of it today, but everyone is building towards it. AI code generation represents a third wave of development workflows - from waterfall to agile to AI-driven - and every major shift in how developers work creates an opportunity to reinvent how security is delivered. The outcomes stay the same: secure code and patching, but the workflows and underlying technologies change completely.
What is AI Code Security
AI Code Security is a category for solutions that provide AI coding agents with tailored security and business context to generate secure code, while giving security teams visibility, findings, and guardrails across their code base. The category will combine several emerging products: continuous threat modeling and design review, developer MDM, AI code review, AI SAST, and AI pentesting.
Rather than being rooted in a fear of AI generated code, this category takes advantage of the opportunities AI presents, completing the vision of shift left by automatically remediating vulnerabilities while shipping more secure code.
The Current Approach Won’t Scale
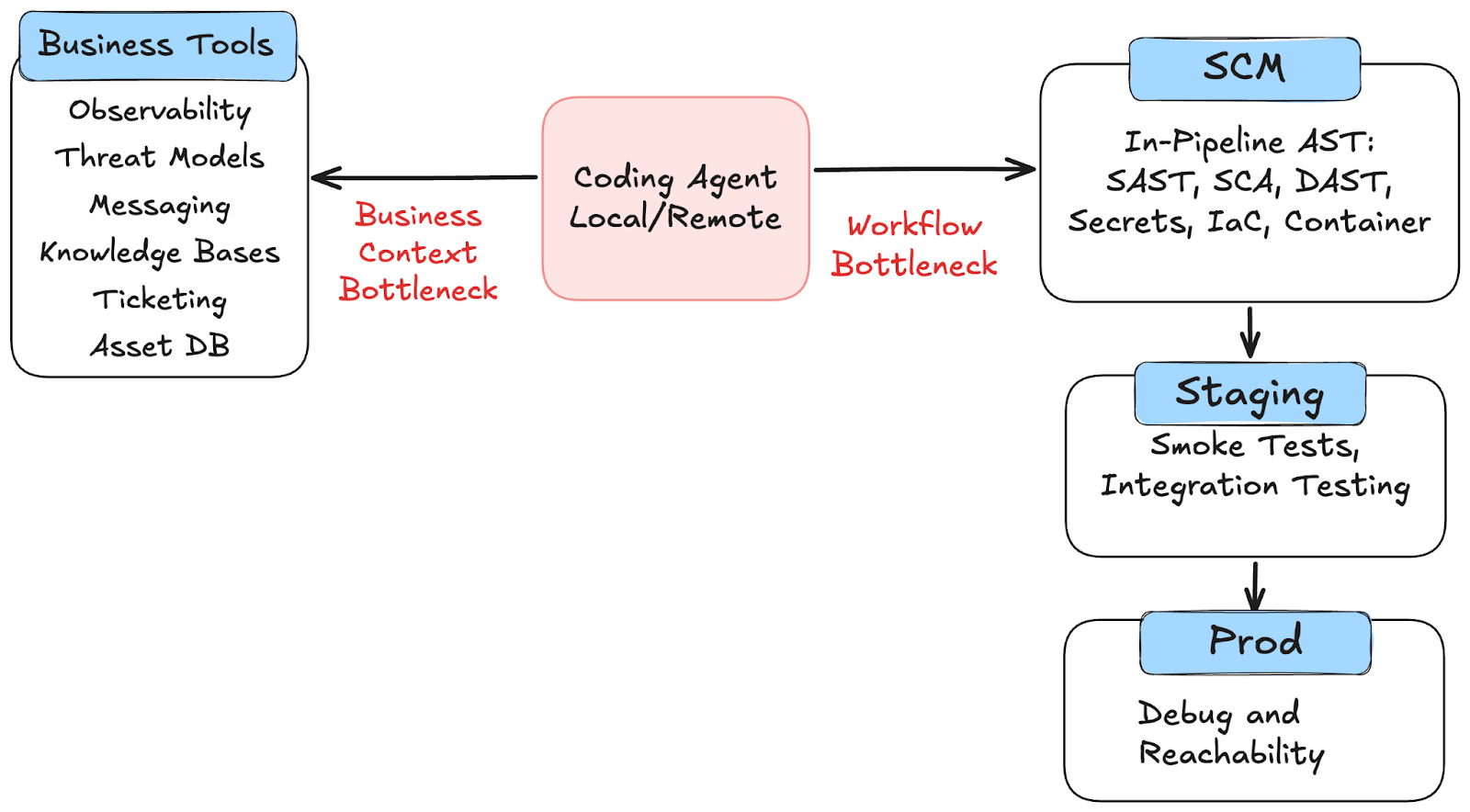
Current application security scanning platforms have focused on building scanners that can run in the pipeline, and provide feedback to developers as quickly as possible. These platforms enabled the “shift left movement” by promising to stop vulnerabilities before they were deployed.
The wave of shift-left solutions face several fundamental challenges that go deeper than “too many false positives:”
Vulnerabilities are discovered over time, and can’t be made “secure by default” - patching is the bottleneck, not discovery
No amount of secure developer training or code scans can force secure coding patterns
Architectural complexity and developer velocity make design review unscalable
Business logic exploits are the most common exploit types, but cannot be detected by deterministic scanning
These challenges are due to two bottlenecks traditional tools have had: a lack of business context, and the complexity of the scanning workflow. First, traditional tools have failed to suggest contextual findings and fixes to your organization. Tools can find a SQL injection, but they can’t tell you what ORM you should use to fix it, or the risk of deploying that fix in the first place. Second, the workflow of traditional tools is built for humans, not AI. Shifting left makes security place speed bumps in front of developers, but AI agents need the feedback before they start coding, not after.
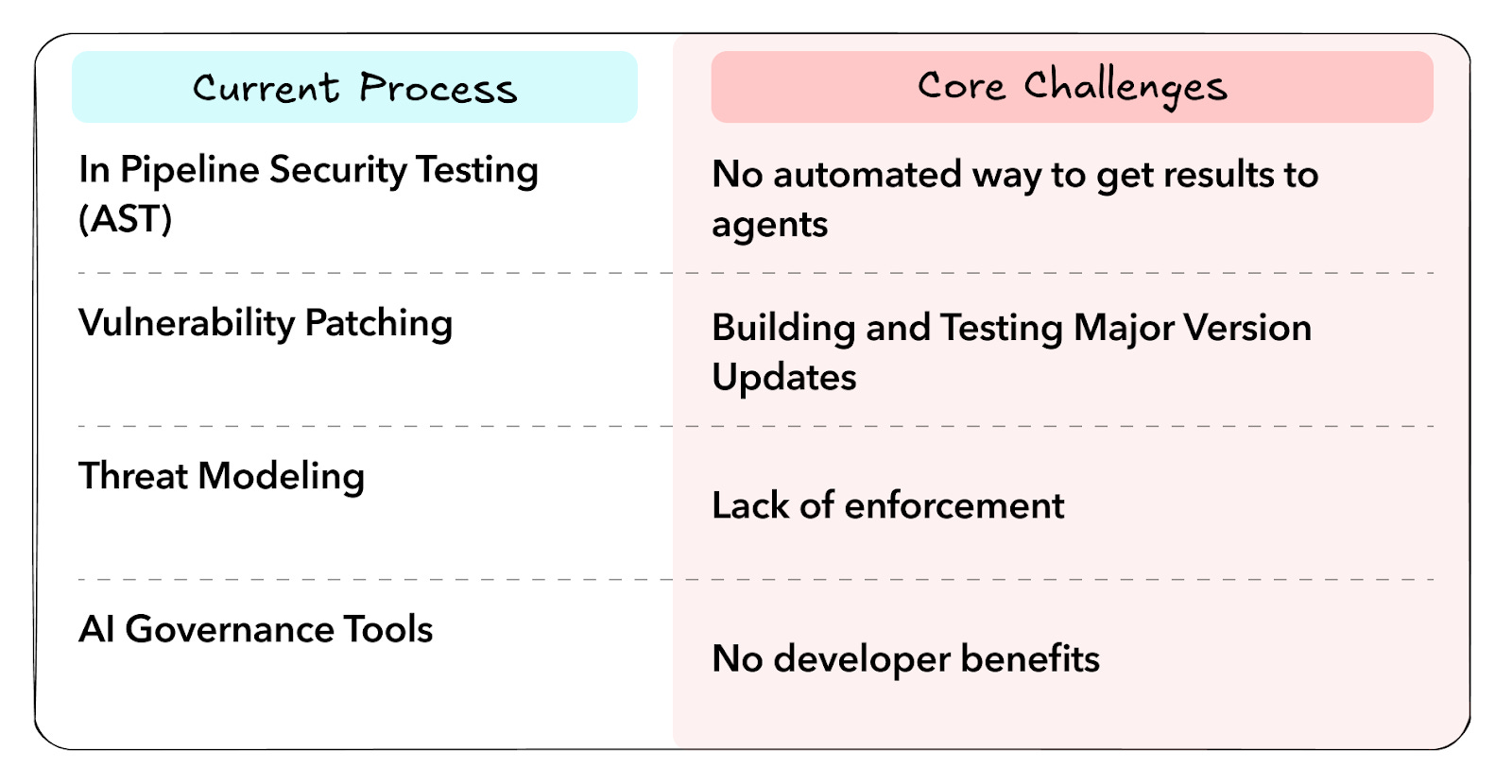
AI Code Security tools focus on maximizing the value of AI Code Generation for Security teams, rather than the risks of using them. They’ll focus on providing teams with guidance on how to fix their security issues, while giving prescriptive advice for security agents. The result is improved remediation workflows, stronger code generation, and a more effective realization of shift-left principles, reducing vulnerability backlogs while giving security teams the oversight they need.
How AI Code Security Works and Why It’s Needed
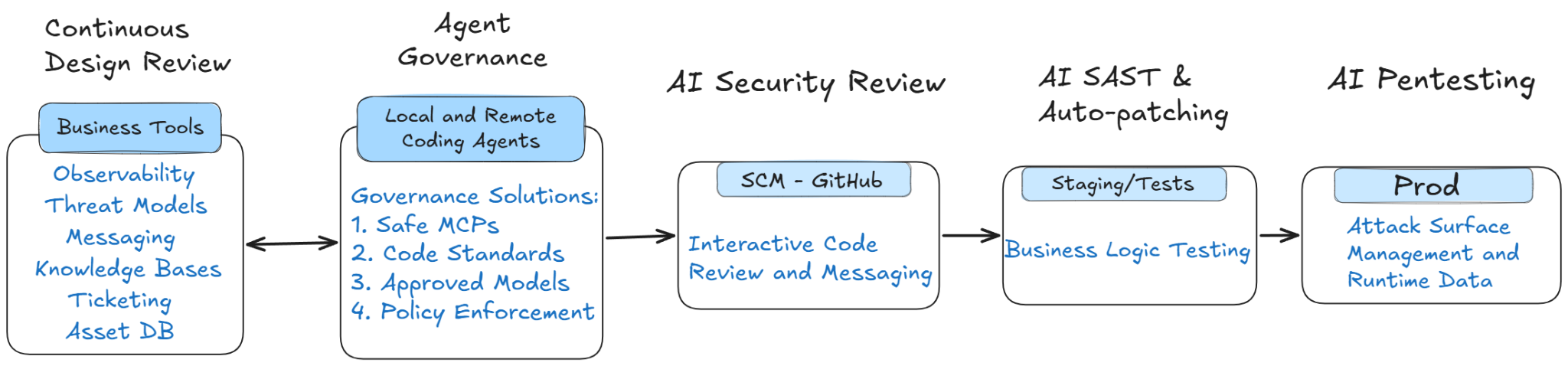
With the right contextual guidance, AI code generation enables two primary opportunities: first, the effective remediation of backlogs, and second, secure by default code generation. The first addresses the challenge of getting organizational buy-in to fix security issues. The second addresses the challenge of building and enforcing security standards unique to your organization.
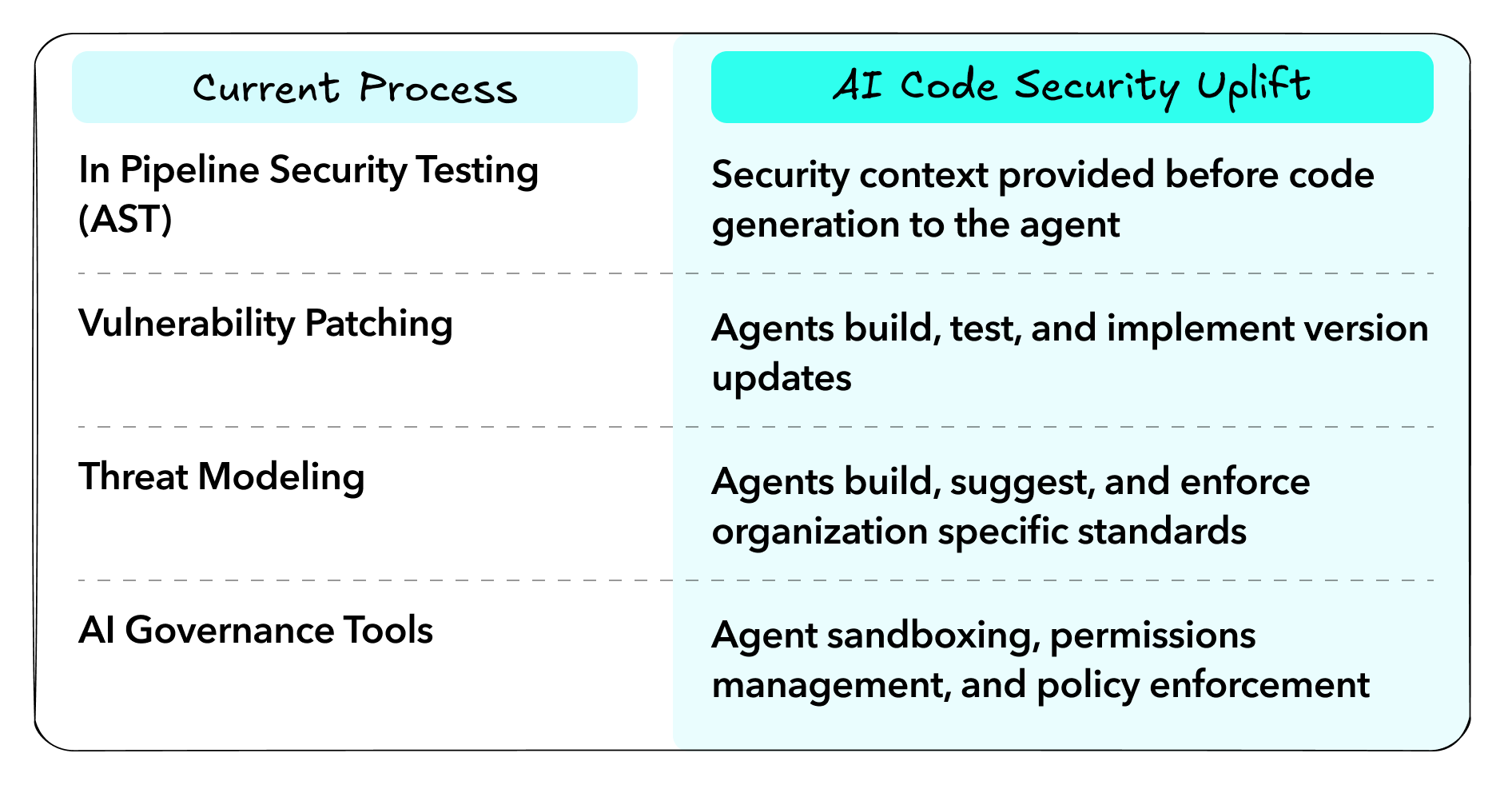
AI Code Security solutions begin by analyzing your attack surface, code, and knowledge bases to build a contextual knowledge graph of your product, its goals, and architecture. This contextual graph is the underpinnings of the outcomes these solutions deliver: threat models, contextual security findings, and secure code generation. This knowledge graph is only possible thanks to AI’s abilities to parse contextual data, making the entire security process customized to your organization. Building and enforcing this knowledge graph requires the following four core technologies: threat modeling, AI AST, interactive review tools, and developer MDMs.
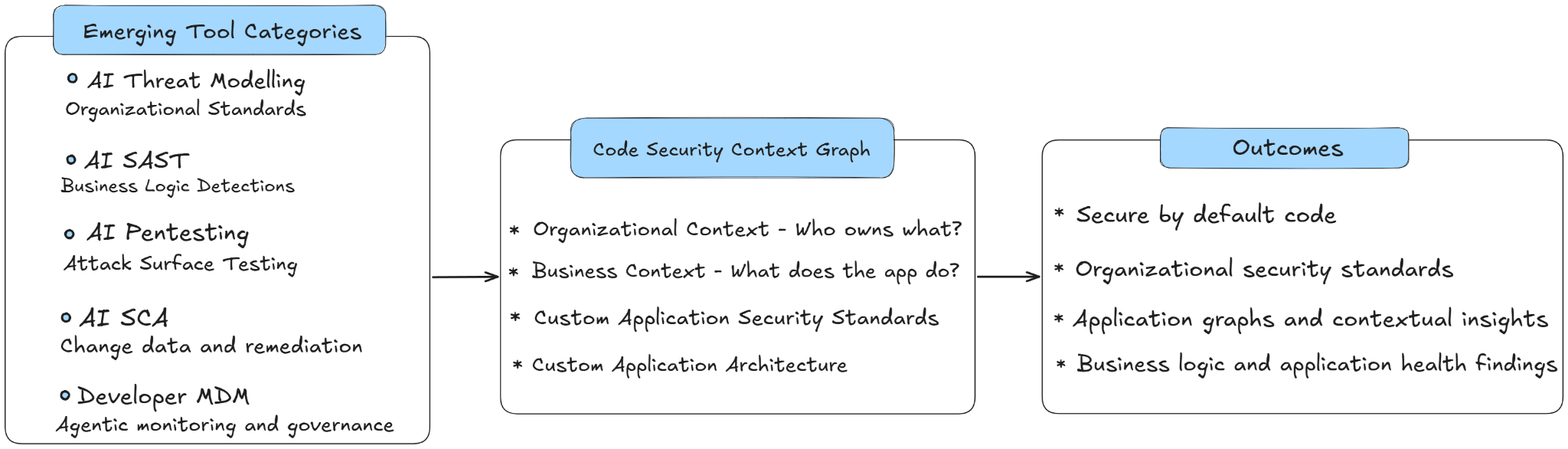
First, threat modelling and design review are the foundation of security, but oftentimes treated as luxury investments. AI enables continuous review and enforcement by integrating with a company’s existing documentation to give teams insights into potential threats, while providing guidance on what policies to implement to prevent them. For example, AI Threat Modeling and Design Review tools give teams not just necessary documentation, but guidance on what secure coding practices they need to implement.
Second, AI is transforming traditional scanning capabilities - from SAST to DAST. AI native SAST tools provide a generational improvement over traditional SAST by using contextual graphs to discover novel findings across a code base, and suggest remediations. While this outcome is the closest to existing scanners, the findings themselves are categorically different - discovering unique logic vulnerabilities, while reducing false positives based on holistic application contexts. These capabilities are found across three emerging categories, none of which are all done by a single vendor: AI SAST, SCA autopatching, reachability analysis, and AI Pentesting. While threat modelling provides proactive guidance, AI testing provides the backlog and vulnerability contexts.
Third, the way that teams are interacting with their tools is changing from static scan results in PRs, to interactive chat experiences with coding tools. Security tools are evolving to fix their own issues without interfering with developer experiences by handing the work over to a background agent. Furthermore, teams are looking for ongoing and automatic guidance around their coding decisions, and what features to implement.
Finally, teams need a way to deploy and enforce these secure coding guidelines. We wrote earlier about the emerging capabilities of Developer MDMs, which allow the enforcement of AI coding standards as a side effect of providing broader governance of developer endpoints. Teams need the ability to govern developer endpoints, while enforcing their security rules to generate secure code.
When these capabilities are combined, teams get an end to end solution for securing AI generated code:
A threat model is generated specific to your organization and application
AI testing discovers and validates existing issues, while continuously assessing new deployments
Agents automatically gather security context when applicable to their task to improve and standardize code
Why This Matters for Security Leaders
Executive leadership is pushing for AI adoption, but security is still expected to govern the adoption. Teams need new capabilities to adopt and enforce standards as fast as AI code generation is happening. Security teams need governance capabilities for safe AI adoption.
Why this is Important for Practitioners
Practitioners are stuck using an outdated model of scanning, creating developer friction rather than adopting the new possibilities AI enables. In the long run, this new category of tools will make security’s job easier, not harder. AI Code Security tools will give teams more time to focus on higher level architecture research rather than prioritization and remediation.
Capabilities Guiding the AI Code Security Market
Build your own AI Code Security
Many security teams have already begun rolling their own versions of pieces of this solution:
Create a centralized repository for security use cases and best practices, giving developers guidance on what tools and techniques are used.
Complete threat models and design reviews on ongoing projects, and update existing documentation accordingly.
Give this context to your coding agent of choice in the way that best utilizes the context window. This might mean rules files, skills, MCPs, or a combination of approaches.
Continuous threat modelling and design review vendors

Vendors in this category connect to your code and knowledge bases to create an ongoing threat model of your environment. They can then provide AI generated design reviews for upcoming changes, as well as flagging major changes that are in progress. Leaders in this emerging category also offer in pipeline enforcement to make sure defined security standards are being enforced. Startups in this category are Clover, Prime, Seezo, and Devarmor.
AI SAST and AI Pentesting
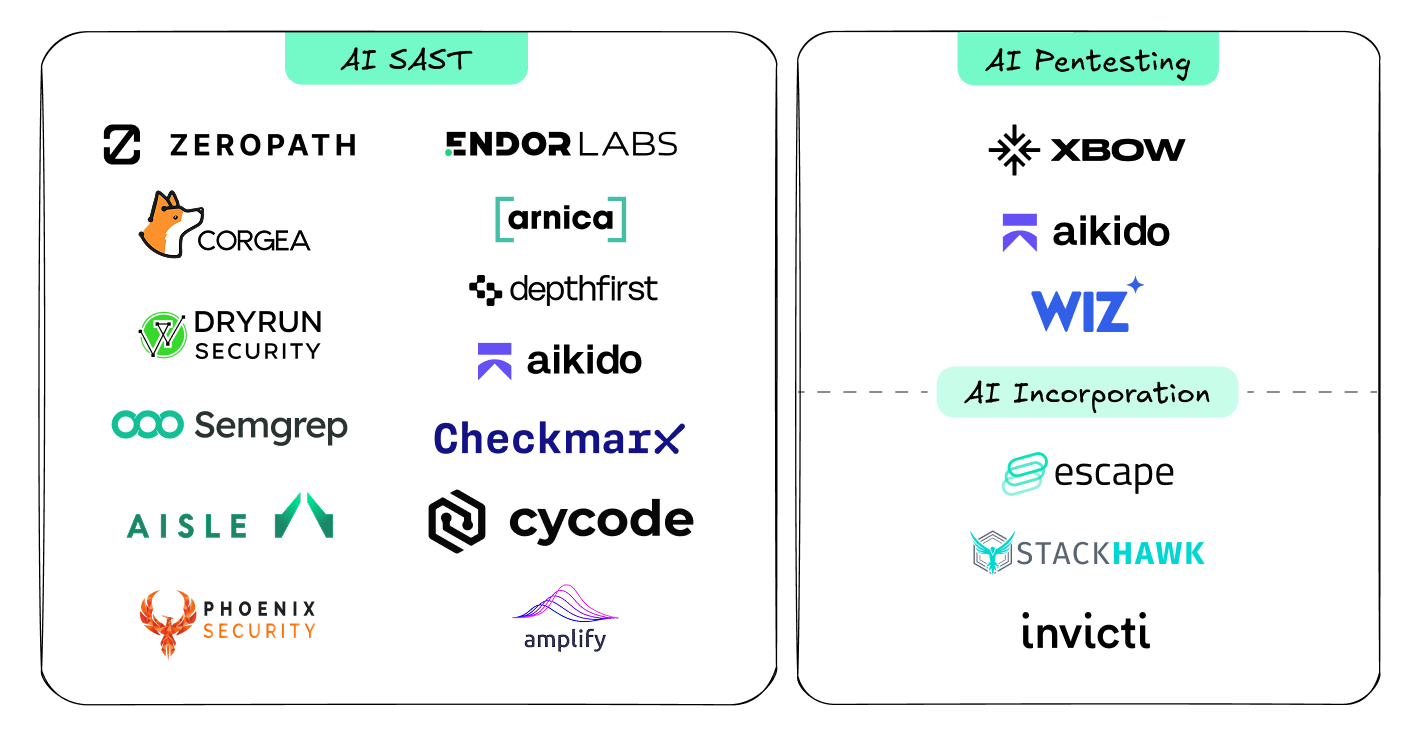
In the application security report we highlighted all of the vendors associated with AI SAST and AI Pentesting; however, we didn’t fully break out the AI methodologies taken by these companies. In this context, the AI Native SAST approach that uses LLMs to explore tagged syntax trees is most relevant. Providers that we know work this way are Zeropath, Aisle, Depthfirst, and Corgea - this distinction is important because it benefits from the data imported from the threat model.
Agentic Code Security Management

When it comes to enforcing coding standards, there are two general capabilities:
Fetching organizational context to the agent without disrupting its workflows. Corridor specializes in this approach, but we’ve also seen less sophisticated versions from other vendors.
Governing permitted AI coding tools on developer endpoints. Backslash is the most mature version of this we’ve seen, but several larger application security platforms such as Snyk, Ox, Pillar and Legit provide versions of these capabilities.
These capabilities provide both the endpoint and agent governance teams need to enforce the context created by the other tools.
Conclusion
This article focuses on the future requirements of the market and how a new category, AI Code Security will be built to deliver the solution. There are several emerging products that help secure AI generated code, but we’re excited to see all of the components get put together. Our prediction is that there will be a new multi-billion dollar application security company, and it will be the one that best puts all of these pieces together.
I think this category will be larger than many realize. Let’s say human coders make a security mistake 1% of the time and have an output of 1000, but if coding agents are better than humans then they will only have a mistake 0.1% of the time but the output is 1000x more, then the number of security mistakes increase 100x! I don’t think regulators and compliance teams will let the coding agent company also be responsible for the security/compliance of that code so I’m not sure Anthropic or OpenAI will dominate quite as much as initial reading. I could be wrong.
Konnor's point is interesting - if agent output is 1000x human output, even a lower error rate produces a much larger absolute volume of findings, and regulators are unlikely to let the agent vendor self-certify, at least not anytime soon (?). Someone independent has to score and evidence the output. What I feel missing is an evidence pillar alongside the four you have in the article; whether you see it that way or whether it collapses into one of the existing buckets will be interesting.