

How to Know If the Trivy Supply Chain Attack Hit You
And how to get your Security Operations team ready for supply chain malware

Earlier this week, on March 19, 2026, Aqua’s Trivy scanners were attacked. This latest supply chain malware attack represents a significant advancement in exploit techniques and serves as yet another in a series of endless wakeup calls for security teams.
Previous malware attacks like Shai-Hulud were easier to detect because they generally relied on secret scanners, encoding those secrets (twice for epic security), and then sending them up into a public repo for attackers to scrape. While a pain to deal with, brute force attacks were at least easy to spot: simply scan for the repo prefix to see if you were impacted. The latest Trivy compromise represents a major step forward in attacker sophistication, due to the complexity of fail safes deployed, as well as the usage of C2 servers and encryption over encoding.
This post will focus on why these attacks are so difficult to detect and respond to, and what you’ll need to investigate if you were affected. In the process we’ll see why the industry is fundamentally underprepared for this becoming a major attack vector. For technical deep-dives on the attack itself:
How we learn if a package has been compromised
Very few organizations invest in upstream malware scanning, and we should be genuinely grateful for each of them. While many companies do bespoke research, it’s better to call what’s emerging “open-source incident response” – and it’s being run by an unofficial consortium of researchers making everyone safer. The primary organizations doing this at scale are Aikido, Wiz, OpenSourceMalware, StepSecurity and Socket; but many other organizations such as Datadog, Veracode, Boost Security and others also contribute research.
While we’re grateful for the research, the underlying concern should be that this stuff isn’t magic, and small research teams are doing a lot of heavy lifting – using open source packages is risky, and you need to take appropriate security steps to secure your environments against zero days.
At the risk of being a broken record, detection and response tools need to expand further into the application layer to detect these attacks when they bypass scanning tools and researchers. Just as we have an EDR instead of antivirus, teams need to adopt CADR rather than relying on searching for file hashes after the exploit has happened. You can read more about the latest developments in preventative application protection in our application security report on page 26, the TL;DR is that as AI makes vulnerability discovery and application layer malware more achievable, the patching and praying approach is too slow.
How to understand if you’ve been impacted
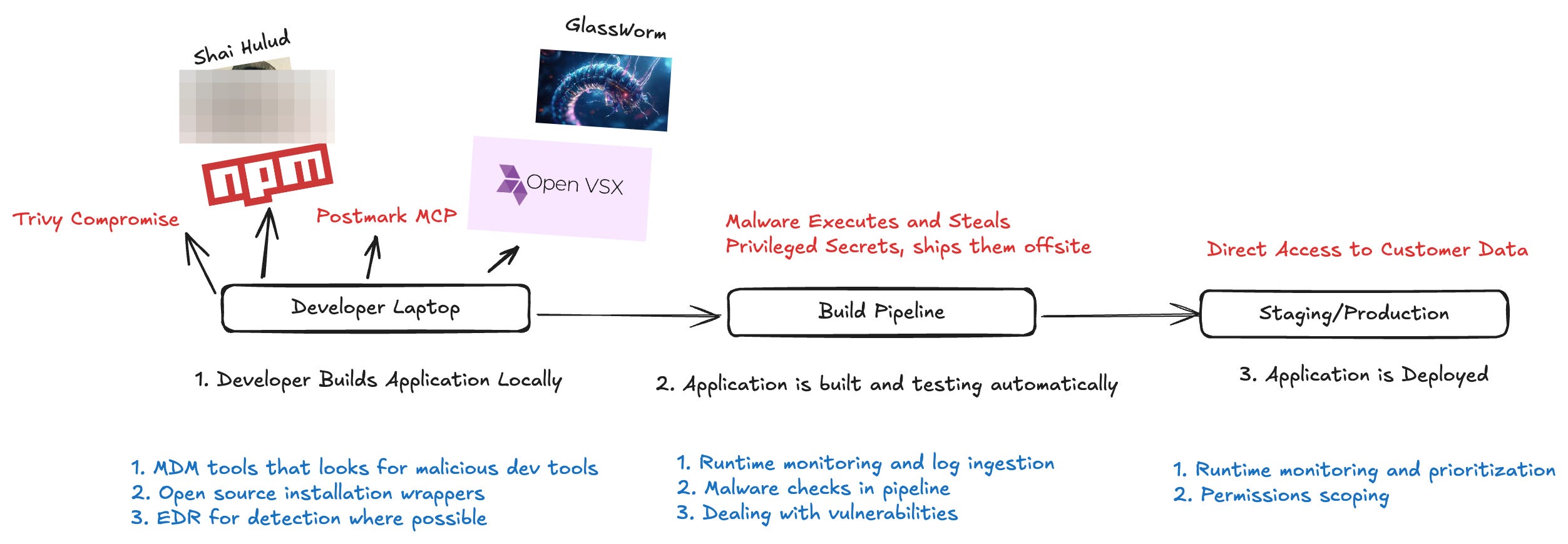
Even if you know that you use affected packages or GitHub actions, most organizations do not have adequate telemetry to assess the impact – and subsequently which secrets need to be rotated. Teams lack telemetry because open source packages get installed everywhere, namely developer machines, pipelines, staging environments, and production. Developer machines and pipelines go especially unmonitored.
In earlier supply chain attacks the blast radius has been lessened by simple mistakes attackers (or researchers) made, such as only working on Github runners, or not properly establishing persistence. The latest Trivy attack shows more sophistication, taking several other paths for optional persistence later, encrypting rather than encoding, posting secrets to an attacker server, and not leaving obvious evidence behind.
IoC’s involve searching for external domain traffic, and monitoring egress traffic for cloud workloads is one of those “we’ll do it later” projects for security teams (one reason I’m a fan of cloudfence). If you’re building your own telemetry, here’s what you need to be able to have quick access to search:
Developer laptops for installed package versions, egress traffic to attacker domain, file hashes once provided by a vendor. Typical tools: EDR, local vulnerability scanning (SCA), firewalls.
Github actions logs and egress traffic. These are extremely rare for organizations to have in a consolidated location, if at all in the case of egress logs. Typical tools: SIEMs, observability tools, eBPF sensors and CDR tools.
Staging/Production file hashes, package versions, and egress traffic. Most organizations do not fully monitor their egress traffic - another benefit of CADR runtime tools. Typical tools: CADR, Container Vulnerability scanners (CNAPP).
In short, being able to know if you’ve been impacted is not automatic: it requires a lot of pre-emptive work to make sure you’re equipped to respond.
How to respond If you’ve been impacted
There’s one line in most of the response blogs that’s easy to say but hard to achieve: “assume total compromise of the system and rotate all credentials.” For most organizations, this project alone ends up being a fire drill made worse by the kind of persistence that impacted Trivy in this case. If all tokens aren’t invalidated first, and then reissued, attackers can use the permissions of an established token to see the newly generated ones.
For most companies, this means guaranteed downtime, and is a complete nightmare:
Identify scope of the compromise: which secrets have access to which permissions, which themselves may have access to further secrets downstream
Universally deactivate the secrets, or in cases where refresh tokens may be issued (such as AWS), apply a universal deny policy to the identity before deactivation
Issue new tokens across workloads.
For most companies, this is far from trivial, and it’s almost a guarantee that things will get missed. There are many approaches worth spinning up sooner than later to avoiding these pain points:
Use JIT wherever possible for human and non-human identities
Have a clear process in place for secrets rotation, using an external secrets manager rather than hardcoded keys
Scoping the impact is the harder part; to be frank, there isn’t a great way to do this yourself and is the primary benefit of NHI security providers - showing token relationships and permissions, and monitoring them for indicators of compromise.
How to prevent supply chain attacks
Preventing supply chain malware is challenging, because there are so many forms it takes. Did the attack compromise hosted actions? A new package version? An old one? Here are the basic steps to take:
As stated everywhere: if you’re using open source github actions, pin to version SHAs rather than version numbers. Yes this is a pain, yes it makes updates harder, but this is the most likely attack vector.
Scan for secure workflow configurations
Restrict the access of Github Actions across your organization: Follow Github’s guide to use actions with the least privileges required.
Lockdown your open source installers (there are several open source tools for doing this, and your default installer might have them as configs such as pip):
Require a cooldown period of one week before version updates (yes this ironically means slower patching for vulnerabilities)
Disable pre and post-install scripts
Expand your data pool for SBOMs to include packages installed on local dev machines, pipelines, staging, and prod environments.
The unspoken assumption behind these preventative measures is they require that malware gets flagged upstream rather quickly. This is something organizations shouldn’t count on, and why preventative ADR capabilities that prevent malware execution in third party packages is so important.
What should you do if you’re an open source maintainer
Open source maintainers are under a lot of pressure already, and preventing supply chain attacks offers yet another headache. In addition to the above steps, maintainers should:
Enforce MFA on all the things - GitHub and package registries
Audit and cleanup user permissions and unused tokens
Stop using Github classic tokens
Migrate off of long-lived tokens for deployments, and sign releases
Conclusion
These attacks are only getting worse and scarier, and if you don’t have these things in place you won’t even know you’ve been impacted, and you may find yourself propagating the next major attack. To use a dated reference, we’re all one malware away from all being Solarwinds - turning our software into distribution centers for more malware.
The core problem is that we treat open source software as trusted software, akin to installing from an app store where every application is approved by a vendor. Unfortunately, Open Source operates more like a shared responsibility model, one where the provider doesn’t actually own any of the responsibility. While Application Security teams have an established practice around vulnerability management, responding to incidents in open source packages is a discipline more akin to security operations, who oftentimes lack the necessary telemetry and training required to respond.