

5 Steps for Creating an AppSec Program
Threat Model -> Design -> Scan -> Scale

A few weeks ago, I was able to have a great conversation with Shaun Blackburn about strategies for vulnerability management. Shaun has been at the forefront of a lot of cloud vulnerability management, being in leadership at AWS, Netflix, Airbnb, and now Gemini.
One of many helpful takeaways from that conversation was the stark differences that exist in organizational capabilities when it comes to vulnerability management. Netflix’s approach here is well documented, and many orgs attempt to copy it. The building blocks are automated quarterly rebuilds of all infrastructure, and creating re-useable components for application developers to deploy their own secure infrastructure.
In less engineering obsessed companies, this can come across as an impossible standard, as existing infrastructure looks more like abstract art than anything elegant. In my experience, actually getting paved roads built relies foundationally on strong relationships with DevOps/SRE, and secondarily on strong engineering skills combined with the free time to focus on them. Unfortunately, at a lot of orgs, these things are really missing. More often, SRE teams and Security teams are both drowning in work unrelated to these projects, and have little time to come together to create scalable initiatives. Here are 5 practical ways to get started doing application security no matter where you’re at.
1. Create or Update an Application and Infrastructure Diagram
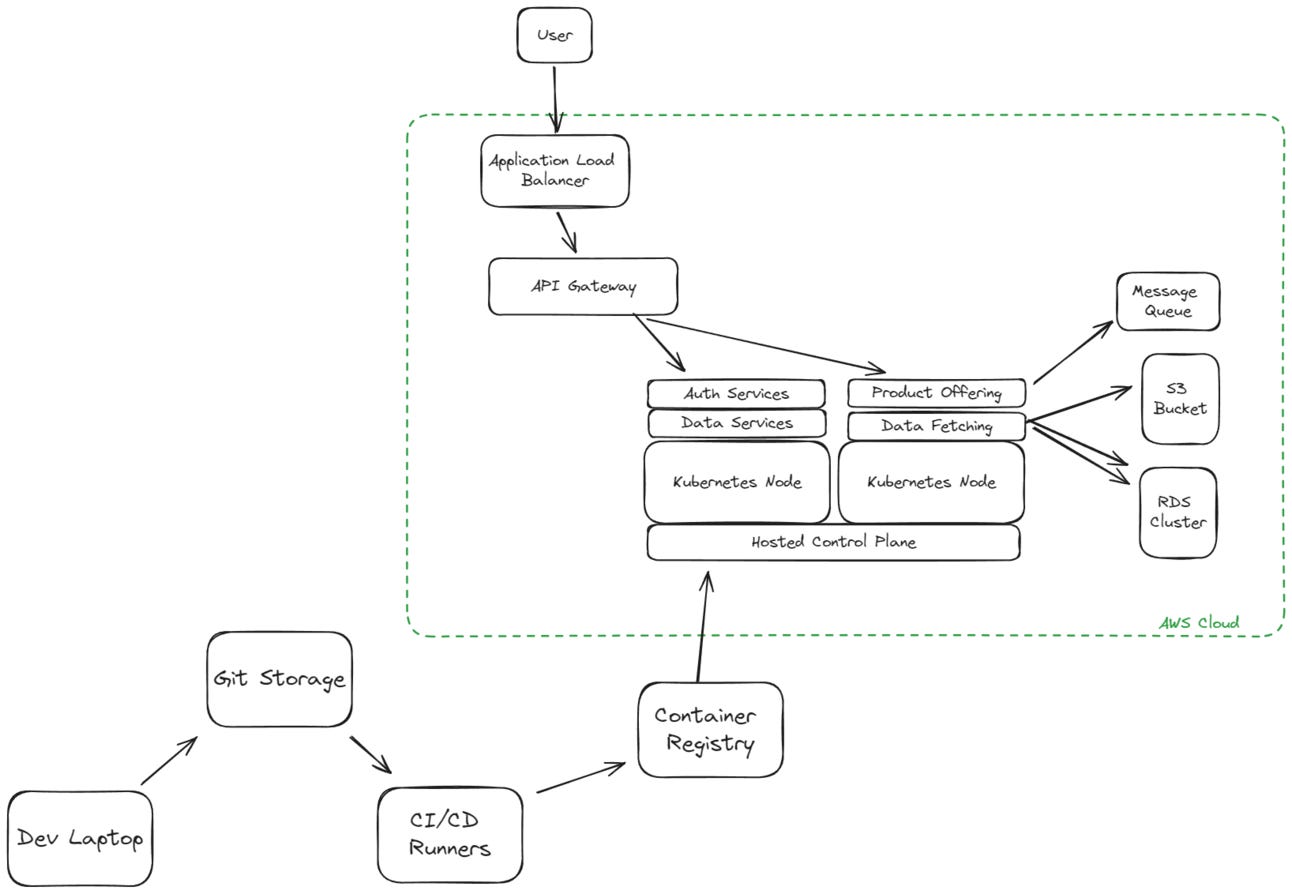
Most organizations have an old diagram sitting in Sharepoint or Drive from 3 years ago that no one has quite taken the time to update. This diagram is the starting point of application security - you can’t secure something you don’t understand. Making this your first project has several benefits:
It’s something engineering teams recognize the value in doing, but no one has time or incentive to do it.
Senior engineering leaders are usually the ones who have this information, so it’s a good reason to create those relationships.
Meeting with teams around this diagram will usually unveil security concerns they have in the process.
I would suggest creating this diagram from two perspectives, sometimes even creating two separate diagrams. The first is primarily focused on deployment processes and overall application architecture from the inside. The second is focused on the actual product user experience, and following sensitive data.
The first “Deployments” diagram should answer these questions:
How does code get from a laptop to production?
What technologies do we use across our applications?
What are the sources of truth for where our services get configured?
The second “User Experience” diagram should answer these ones:
To what services does a user send their most sensitive information?
Where is that information stored and how is it accessed?
What services have the most amount of user interactivity?
2. Map that Diagram to your Existing Security Tools

Now that you have your diagram, you can begin thinking about your existing security tooling, and if it’s really a good fit or not. If you have a traditional security stack, it’s possible that your SIEM is ingesting some of these logs but has other gaps, for example application logs but not Kubernetes audit logs.
I do think it’s important to not go chasing down every log source, because the logs are only as good as the detection rules you build around them - and that can be its own process where it’s better to bring in a vendor to supplement your weak points. Instead, try to be realistic about the most important logs that you already have ideas for good rules.
This is why we start by mapping your existing tools: you can’t go looking for new vendors before you understand what your existing ones are doing. If you’re just getting started with application security, it’s likely you already have a SIEM and an EDR - these usually cover non-Kubernetes workloads and some cloud logs. You may also have a CSPM or CNAPP - the heart of these tools will be better vulnerability scanning across your workloads.
In most cases, ASPM will be the first major net new tool selection you make. I’d highly suggest a few things here:
Scan some core applications with open source projects like Trivy and SemGrep to get a feel for what these results look like and how much lays ahead of you. This will also help you understand permissions you’ll need to set scanning up.
If you’re starting from zero tooling in pipeline, webhook based all in one scanners will be the easiest to get up and running with, such as Ox Security, Aikido, and Cycode. (Full list here).
Don’t buy anything before you end to end find and fix an issue with it, to make sure you’ve identified any missing needs you have along the way. We have to recognize that these tools are fundamentally work generators, and not autonomous solvers (yet).
3. Recognize Tool Limitations
There are a few important things to recognize about what tools do and don’t do for you here:
You’re essentially buying visibility, but this will come with a lot of work. Really recognize and digest that you are buying a work creation tool, and make sure leadership is aligned and okay with that.
Build as if you’re already considering switching vendors - this space is changing really quickly, and you may want to supplement or replace existing solutions along the way. Find tools that are easy to put in, they’ll also be easier to take out (most of the time).
If you already feel like you have decent visibility, consider a CDR or ADR provider instead of ASPM.
Don’t evaluate primarily based on “Stop the Bleeding” or “Pipeline Blocking” as the way you’re going to stop vulnerabilities - these functionalities are good to have, but they fundamentally misunderstand how vulnerabilities happen. Vulnerabilities get introduced because code doesn’t get updated far more often than because a developer is introducing something new.
Vuln management is really a tool to get tech debt addressed. Most of your scanners will provide the ammunition your developers need to highlight the importance of updating or deprecating dead services. Once again, you need a lot of leadership alignment here.
4. Create Repeatable Processes
Now that you’ve done some scanning evaluations, it’s time to turn those into repeatable processes developers can use. Here’s some advice on how to do that:
Don’t get over-sold on where the results show up, e.g. in PR comments, in the tool, via a web link, via Slack, or via Jira. At the end of the day, what matters here is flexibility. Different teams have different workflows - some might only want PRs raised, while other may want a Jira workflow with clear due dates.
Don’t treat vulnerabilities as alerts. If you’re sending pages or slacks for every vulnerability detection, developers will quickly stop paying attention.
Encourage developers to not approach every ticket with the goal of determining if they’re actually vulnerable or not. Instead, the goal is just trying to patch. Patching is often easier than assessing or trying to recreate a PoC.
Make sure everything you do is tied to a real security or business outcome. People will quickly get frustrated by policies from security that serve no obvious purpose - such as blocking on CVEs that are obviously not exploitable.
Learn how patching really works and try some yourself alongside your devs to understand the issues.
5. Do the Important Stuff
While you’re implementing some of this scanning, it’s important to recognize that scanners and remediation are not all there is to starting application security. There are a few pretty basic things you can implement that go a long way towards improving security, and giving you less scanner results in the long run.
Create a workflow that allows security to be involved early in product decisions, teaming up with DevOps/SRE is a great way to do this
Rebuild your base images nightly to get the latest updates. You do not need to change versions or anything, simply perform a nightly rebuild! Here’s the schedule action in Github actions as an example.
Build terraform modules that should be used with secure defaults, like setting encryption to true.
Explore runtime visibility with agents like those from Oligo, Upwind, or Sweet.
Include DAST in your pipeline with next gen API security tools like StackHawk or Escape.
Deploy low hanging fruit security measures like WAF, custom detections based on application logs.
Help everyone by making things sensible - clear and simple cloud roles, tests, pipelines. Simplicity goes a long way to increase security, gaps often squeeze in with complexity.
Map out third party data flows, optionally using tools like Riscosity