

Defining Reachability - is it just hype?
(1/3) Exploring what's been up with reachability since our last talk about it

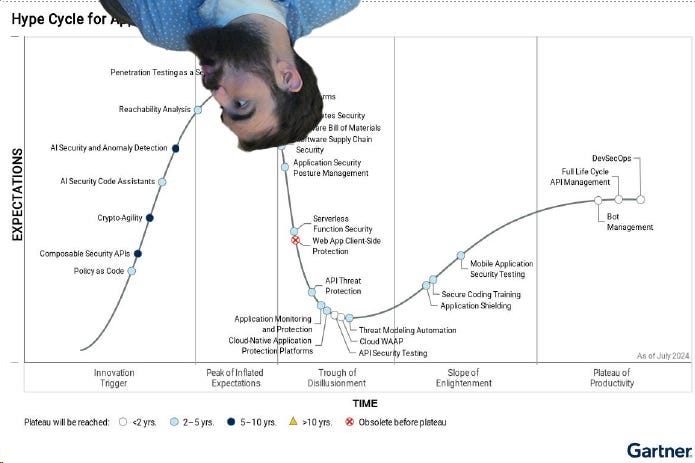
I was surprised to see reachability pop up near the top of the latest Gartner hype cycle. It’s been around longer than a lot of other stuff out there; however, I’ve seen modern iterations get really really good. We’re approaching reachability zenith. I’ve written before about reachability - once with Endor (not sponsored), and once tepidly on its potential with pros and cons. Since then, runtime and static reachability have both improved tremendously, so I’m back on the hype train, but with two caveats:
Reachability is seen as mostly a false positive reduction methodology, but I’m arguing it’s actually meant to get us closer to the goal of vulnerability scanning - stopping potential attacks.
Fixing findings is still the long term hard part - but reachability will always be useful alongside the fixes. I used to view this as an either/or problem. Now I view it as both/and.
In my career securing cloud native applications, I have never seen proof of an exploitable CVE from a container image the context of my SaaS application. That’s despite thousands of vulnerability scans, with millions of discovered vulnerabilities, and untold developer hours fixing the things. The unfortunate truth is that the staggering number of false positives have caused real harm to security’s legitimacy in their organizations. In business terms, I’ve spent hundreds of thousands of dollars on vulnerability scanning with very little to show for it - the value has been in the software and cloud visibility more than CVE detection.

It’s honestly difficult to even quantify the amount of time and broken developer relationships that have come about due to the astronomical amount of false positives detected in vulnerability scanners. In this article, we’ll talk about the two kinds of false positives that exist, and why reachability is our best chance at solving the nightmare that is vulnerability triaging.
The goal of vulnerability scanning

At this point, vulnerability scanning has become a de facto requirement for most organizations. The goal of vulnerability scanning used to be much more simple: to patch software that could be exploited. For example, a vulnerability in a version of Microsoft Word might allow attackers to run a malicious macro. The solution? Patch your version of Word.
Fortunately and unfortunately, modern software and scanners have radically changed what these scan results mean, especially in application contexts. In the “good old days” vulnerability scanning broadly just meant looking at Windows updates and common software like Adobe. Now, scanners can expertly pick apart binaries and file systems to hunt for vulnerable transitive dependencies across your systems.

Now, much to security’s benefit, vulnerability scanners go much deeper than they used to - looking at the full stack of components that make up each piece of software. While this is undoubtedly a good thing for visibility and accountability, it has conversely increased raw vulnerability counts to a number that security teams just can’t keep up with.
When it comes to false positives in this context, I see a lot of confusion on both vendor and consumer sides. There’s confusion because these findings both are and are not false positives. They’re not false positives in the sense that “vulnerable” versions of those components really do exist on the machine, that could be exploited under a given set of circumstances. However, I call these cases of unexploitable vulnerabilities false positives because the point of vulnerability scanning is to detect exploitable software. If something isn’t exploitable, it’s simply not vulnerable.
IF SOMETHING ISN’T EXPLOITABLE, IT’S SIMPLY NOT VULNERABLE.
As a simple example, the regreSSHion vulnerability last month was exploitable if a server is open on port 22. If a server isn’t open to SSH connections, it’s not vulnerable. If the OpenSSH library isn’t loaded and accepting network traffic, it’s not vulnerable. To be clear: patching is still a good practice. That server could become vulnerable. But the cold business truth? There is zero real value in patching when you’re not vulnerable - you were just as secure before and after doing so.
The security guy in me has a hard time with that reality, because good security has layers of defenses. What if someone makes it public? What if an attacker finds a way onto the system? But, from a business perspective, if I was allocating 10 developers to a new feature or fixing a non-exploitable vulnerability, they’re going to be working on the new feature every time.
Traditionally, compliance has been thing that forces even these findings to get patched; however, in the face of floods of vulnerabilities from the open source ecosystem, auditors are getting more and more on board with explaining the exploitability of findings. This is most apparent in VEX statements for SBOMs, which allow you to argue why you’re not vulnerable to a finding - truly the thing that might save SBOMs relevance.
How Reachability Helps
I generally separate the solutions to our vulnerability problems into prioritization and patching solutions. The patching half of that is making fixing easier by surfacing ways to fix findings and giving developers the tools they need to understand their code changes. The prioritization half really is meant to return vulnerability scanning to its goal: finding exploitable software. I’ve done vulnerability management for so long that it feels like the goal is really just compliance, but it exists in those frameworks for that purpose: stopping potential exploits.
RETURN VULNERABILITY SCANNING TO ITS GOAL:
FINDING EXPLOITABLE SOFTWARE.
Determining if something is exploitable or not is much more complicated than it might seem, especially given macro issues that exist with the quality of CVE data itself. Many vendors go so far as to create their own proprietary databases to try and add some more quality to the vulnerabilities themselves. This is why every vendor who says “we do reachability!” means something slightly different, determining exploitability requires a lot of environmental context.
The goal of reachability then is to determine if something is actually exploitable or not, and that makes it so any “flavor” of reachability has the potential for good.
Knowing all of this is helpful information for example:
A library is loaded
A function is called
The workload is internet accessible
Likelihood of exploitation via EPSS
The kind of data processed by the library
If an existing control would mitigate the exploitation
With these considerations about vulnerability management in mind, I’ve begun to see the goal of reachability less as false positive reduction, and more as true positive identification. If the point of vulnerability management is to stop exploits - we need to identify what is exploitable.
Conclusion and Future Parts
I wrote in another place about static reachability being a great solution here, because the feedback gets back to the developers the fastest. However, it has a problem based on our definition: if reachability means determining if you’re exploitable, and identifying true positives, that can only be done perfectly at runtime. Part 2 will elaborate on that comparison between runtime and static reachability methodology.
Static reachability will always be theoretical, and so no matter how good it gets, it can’t cover every type of vulnerability, and it can’t know for certain if something is executed. A simple example: in my test repo there is a ransomware script that never actually executes. That script is just there to see how tools think contextually about files they’re seeing at runtime. Every static reachability tool can’t help but surface these results as though they’re true positives. In a real world scenario, these are the tickets that make developers angry, and static reachability can turn down the frustration, but never solve it. A less niche example are test files or data, or functions that never actually execute in context of the running app - or “dead code.”
Runtime reachability however deals in the land of certainty. I was less excited about the prospects of it until I used it myself and saw firsthand the de-prioritization capabilities it can pull off. I’m excited to spend the next two articles diving into this. Part 2 will be an in depth comparison of static and runtime reachability - there are very real pros and cons, which is why great solutions exist in both categories. Part 3 will be the nerdiest content I’ve ever done, picking apart the flavors of runtime reachability and assessing what they’re actually doing. Looking forward to it!
This post is meant to be educational and was completed in collaboration with the team at Raven. This is not meant to be a product endorsement or review.