

Vulnerability Management Part 1 - Assets and Fixes
A three part series detailing what data is helpful for operationalizing vulnerability management (1/3)

The Vulnerability Nightmare

I’ve spent a lot of time over the last year focusing on different ASPM vendors and their capabilities. Many platforms have continued to build into their focus areas: whether that’s first-party scanners, integrating third-party ones, or deepening reachability analysis, these are all bets that may or may not pay off in the long run as vendors search for an all-in-one application security solution.
On the remediation side however, it’s clear that enterprise application security teams are not quite getting what they need from most of the tools that are out there. Vulnerability remediation at the enterprise scale is a different beast entirely, especially when FedRAMP is involved, and one core issue is that most platforms have not built around the asset as a foundational entity.
Most tools in these categories have built around either individual findings (CVEs) or code repos as their source of truth. But as companies grow in scale, much more contextual data about assets and fixes are needed to come up with a risk score that reflects actual prioritization. Here are some examples of where context radically changes the nature of a finding, a critical vulnerability is discovered…
In code that is never actually deployed
On an asset that’s not defined by code
In an environment that doesn’t process sensitive data
That is a duplicate of findings from other scanners
On a component not accessible to attackers
That is mitigated by existing security controls
These considerations make the current vulnerability management processes unbearable. Companies often either hire people to go vulnerability by vulnerability, trying to weigh these different risk calculations against one another, or they build custom scripts to build difficult-to-maintain data science solutions.
I often talk about how DIY vulnerability management isn’t a good use of time for security professionals - you’re hiring someone with deep technical knowledge and having them apply it to data science and project management, functions they’re not equipped for and don’t want to do.
This series of articles will discuss the components of building a proper vulnerability management solution for application security findings. First, this article will address the importance of asset context and remediation guidance, which I view as the two most important pieces of helping developers. The next articles will focus on the challenge of getting findings to the right team based on ownership, and emerging methods of assigning risk and remediation timelines.
Asset Oriented
First, let’s address the importance of a vulnerability tool being asset oriented. The asset in its deployed state is the ultimate source of truth for its priority - both for compliance, and for security purposes. I love shift left security, and I tried to deny the importance of runtime context for a long time; however, the reality of both compliance frameworks and prioritization demand taking it more seriously.
On the compliance side, auditors typically only require runtime scanning and view most of the other scanning places as optional - with regulated environments, it’s impossible to avoid some kind of runtime scan. On the prioritization side, there’s no avoiding runtime as the source of truth. Prioritize findings with every kind of reachability under the sun, if there’s no runtime, there’s no absolute guarantee any of that code is running.
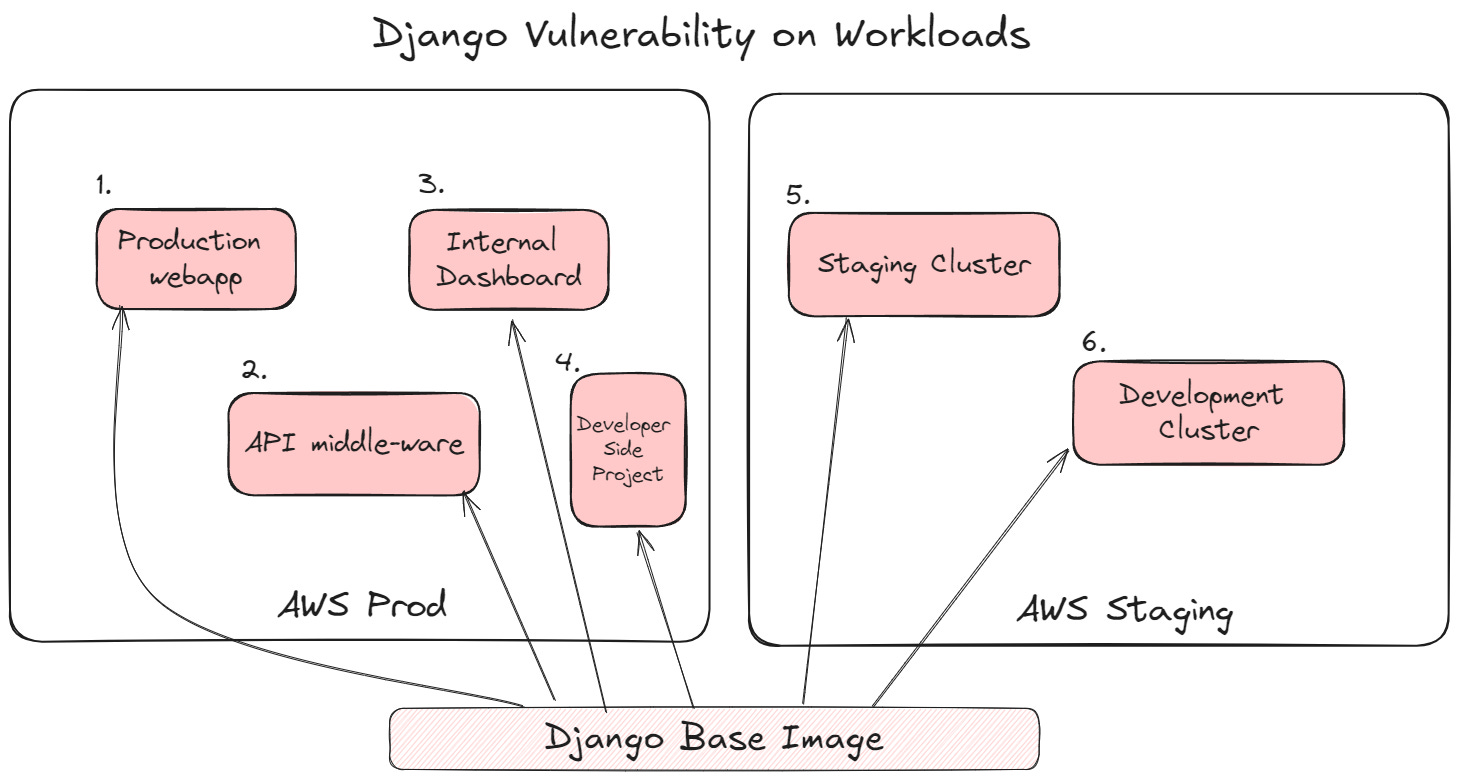
Let’s use a real world example to discuss the importance of asset context with vulnerability remediation. In this example, a primarily Django developer shop uses Django across a variety of different workloads. A new vulnerability is discovered in Django, so the security team is dealing with at least 6 identical alerts here - with only the asset’s location differentiating them.

In our above example, if our Django application is widely deployed, the asset and its context are undoubtedly the fastest way to prioritize our remediation. While I generally think the benefits of things like “internet-facing” are overblown, what really matters is a combination of environmental data about an asset. There is no silver bullet prioritization metric; instead, a plethora of data is needed to query the right data, at the right time, for the right vulnerability.

There are a few reasons that I like how Phoenix Security separates things into Applications that run in Environments, especially for enterprises:
Organizations have radically different approaches to asset ownership. Some have full-blown DevOps practices, where developers own their code out to the assets that run it. More common is a mixed infrastructure team that manages assets to a certain point, followed by developer teams that handle code. Every organization has some shared responsibility model between its infrastructure and application teams. If ownership is to be assigned, a tool needs to be flexible in how it interprets the owners.
When triaging vulnerabilities, sometimes application or environmental context matters more - but they always inform one another. An application running in staging will almost always be less prioritized than an application in production; conversely, a critical vulnerability in a staging application about to go to production should get prioritized even though it’s in a lower environment. Once again, environmental and application contexts need to inform one another, depending on the vulnerability.
This is typically how scanners and responsibilities are segmented at the enterprise level. Most companies use a CNAPP that provides IaC and Container scanning and an application scanner that provides SCA and SAST scanning. I’ve written elsewhere about why these create duplicate results, but it will be long before we see full convergence in any of these tools. Giving teams the relevant data to them makes the most sense with this environmental/application split.
I like product security as the unification of Cloud and AppSec, but it’s still not the reality for most organizations. Typically, organizations have an engineering team devoted to the infrastructure that’s separate from the development teams focused on the code. Segmenting applications and environments allows each team to see relevant information, while allowing those findings to still inform each other.

In sum, different applications and environments both bring their own risk. For example, my production web app is more important than my intranet dashboard; however, my production web app in the staging environment is not as important as my intranet in production due to the nature of the data it processes.
Only robust runtime contextual data can bring immediate prioritization value. It’s important to go beyond manual tagging or minor context and bring the entire code to the cloud and environmental data to a single place. For some companies, the production data may be tagged, for others, it may be in certain repos or folders. Flexibility matters a lot when categorizing assets.
Remediation Oriented
Second, to the importance of being remediation-oriented. Many tools focus too much on the problem of vulnerability discovery and creating dashboards. These tools need more ways to sort large amounts of data into solutions that make sense for your organization. The primary goal here is flexibility because different companies will not operate the same in their fix process. Additionally, the outcome of most of these tools is creating a ticket somewhere, so let’s ensure it’s the best one it can be!
Let’s see this in action with our Django example from earlier. Consider the tickets you will send to developers to get this thing fixed: there is a huge difference in what those tickets will look like based on your architecture. If all of the workloads are deployed from a single base image, you’ll want one ticket to update the base image and then maybe tickets to development teams to re-deploy their services. If however, you manually configure your workloads, you’ll want one ticket to the infrastructure team to remote in and run the relevant patches. How the fix gets deployed is the single most important factor to creating your developer tickets.
While the contextual information helped us to prioritize our remediation efforts, it’s all-for-nothing if we don’t understand where the vulnerability came from, and who can fix it. Security has one goal: don’t look like goofballs, but I’d sure look like one if I created 10 different tickets to different teams to deploy one patch to a base image. In reality, I’d just need one ticket to the team that manages the base images to re-deploy, and then a ticket downstream if we don’t automatically pick up deployment changes.
This is why flexibility is paramount: there are almost infinitely many specific remediation scenarios based on a company. Everyone is at a different maturity in their cloud infrastructure journey, and they can’t afford to be limited by a tool.
Conclusion
In conclusion, we should use asset-oriented contextual data to help prioritize and identify owners and then remediation data to get the relevant information to our developers. We can only understand a vulnerability's priority first based on its context in our environment. The same vulnerability, with the same scoring and prioritization metrics, will exist in multiple places for our organization, and we need to know where to start mitigating first.
Giving developers the wrong remediation guidance is the fastest way to lose their trust. Right or wrong, telling teams to do the wrong things, in the wrong order, or duplicate work is the fastest way to cause frustration, and make security seem like it’s just pointlessly chasing made up vulnerabilities. Only proper remediation guidance helps security teams avoid these pains.
In the next article, we’ll talk about the second hardest piece - now that we have the two pieces of information we need (the context and the fix), how do we get it to the right person?
This post is meant to be educational and was completed in collaboration with the team at Phoenix Security. This is not meant to be a product endorsement or review. All of the tools in this category can be viewed here.