

What is Code to Cloud, and Does it Matter?
Looking at the different types of Code to Cloud and their methodologies


The core of the ASPM/CNAPP/CSPM acronym soup overload is creating “the code to cloud picture.” The primary challenge of cloud and application security in 2025 is security teams being inundated with vulnerability findings, but not knowing where to go, or who to go to, to get them fixed. This is the holy grail of vulnerability management - suggesting the exact line(s) of code that needs to change in order to get something fixed.
Code to Cloud is even more fundamental than reachability analysis, which is a prioritization tool, because it drastically reduces the cognitive overhead of fixing vulnerabilities. It also enables better prioritization, visibility, and de-duplication. The problem? There are a lot of ways that code to cloud can get done, and very few ways that actually work deterministically. When I evaluate the code to cloud capabilities in a tool, the typical flow is turning everything on, wondering why it’s not working, and then the tool’s support team turning some dials on the backend to get things going.
This post will cover why code to cloud is important, before enumerating the pros and cons of some different vendor approaches that are out there.
This post was completed in collaboration with the team at Apiiro who let me use their product to show code to cloud and talk about the methodologies. This is not meant to be a product endorsement or review.
Why Does Code to “Runtime” Matter?
First, it’s worth clarifying that “code to cloud” is the buzzword bestowed upon us, but a lot of this is more about “code to container to deployment” and “code to API endpoint” correlation. The most obvious value of code to cloud, or code to runtime, is giving developers feedback on what to fix, but there are several surprising bonuses. What tends to get most overlooked is how the code to cloud picture actually helps with almost every vulnerability type.
Universal Benefits
1. Finding the Right Person to Fix an Issue
Too often, the remediation steps for a misconfiguration start with a Cloud Security Engineer wasting hours trying to figure out the following:
What does this container image or application do?
Is the misconfiguration essential to making the thing work?
Who changed this?
Why did they change this?
How often will this change?
Where did this change happen?
Usually the answer to all of these questions is found in either a GitHub pull request or a Jira ticket, with comments that address the questions. The challenge is that many security teams are far removed from the rapidly changing nature of their DevOps and Platform teams. It’s ultimately impossible for cloud teams to quickly and easily assign ownership, especially at scale. This is what stops most teams from meeting vulnerability SLAs with any kind of accuracy - it takes the entire timeline just to try and identify who should own an issue!

2. Understanding How Widespread a Problem is
Typically security teams can cause friction with developers by creating multiple overlapping tickets for issues that have a single fix upstream. Even more common than this, security teams end up ticketing the wrong finding, since its source is upstream. To use a simple example, you might ticket a downstream application team with a vulnerability that can only be fixed by a root container image owned by an entirely different team.
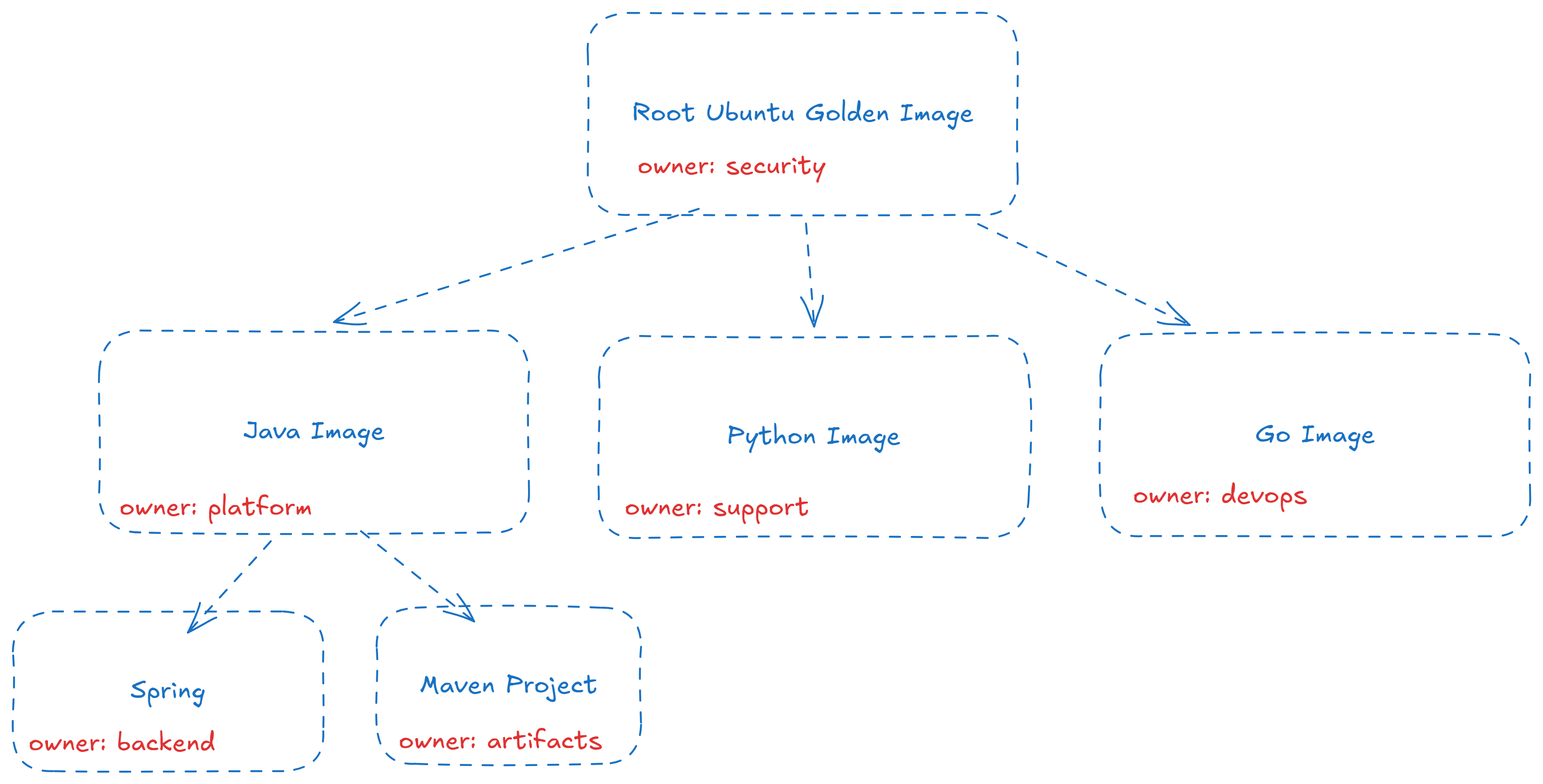
When scanning container images at runtime, teams quickly get a sprawling list of CVEs with no clear indication of their source. Some tools add in container image layers, but these have some fundamental limitations:
They don’t show internal resolutions that happen during a container build. One example is when teams have a golden root image that downstream teams fork to create their team specific images.
They typically only differentiate between the base image layer and manual installations, which doesn’t necessarily correlate to the actual base image that’s being used. For example scanning a from:nginx base image might end up looking like base:debian - which doesn’t help you understand where the fix is.
They don’t point to the source repository of the vulnerability, where one fix can have numerous downstream remediations.
This additional code to cloud data is useful for prioritization, de-duplication, and remediation guidance. Teams can prioritize based on getting maximum value for the investment, they can de-duplicate findings when one Dockerfile is at the heart of numerous deployed containers, and they can tell developers where exactly to make their fixes.
3. Understanding the True Priority of a Vulnerability
While it’s better to discover issues earlier on in a pipeline, the prioritization of an issue can often only be discovered once the code is running in an environment. This is reflected in the nature of CVSS scoring itself, where teams are meant to adjust the scoring based on their own runtime environment. This creates a conflict at the core of application security - you want the findings before the environment is known, but you can only know the severity one it’s deployed. Only if the code to cloud picture exists can you properly score findings - no amount of EPSS or KEV can get you your personalized environments’ context.
For example, Log4J is a KEV with a high EPSS, but the mere presence of Log4J in your environment doesn’t mean it should be prioritized - it might not be accessible, or even used at all in your application. Instead, additional runtime context is needed to prioritize - what API’s are using Log4J, is it being loaded, and what environments is it being deployed to?
In order to properly adjust scoring, you need code context (is this reachable, what files is it in, what’s the business criticality of this repo, what functions are used?) combined with runtime context (what environments is this in, is it internet facing, is it in use?).
Two Kinds of Code to Cloud

Like all good things, code to cloud can be confusing and muddied in different ways. Really what we’re talking about is following a piece of code out to its runtime environment, but there are two ways we can think of that. The first is thinking of what container is running this code, the second is what APIs are accessible via this code. Which approach we emphasize will depend on our personal backgrounds, if you’re more DevOps like me, you’ll think of containers getting deployed, but if you’re more a developer you’ll probably think more of code to its corresponding API endpoint.
“Container to Orchestrator” Correlation
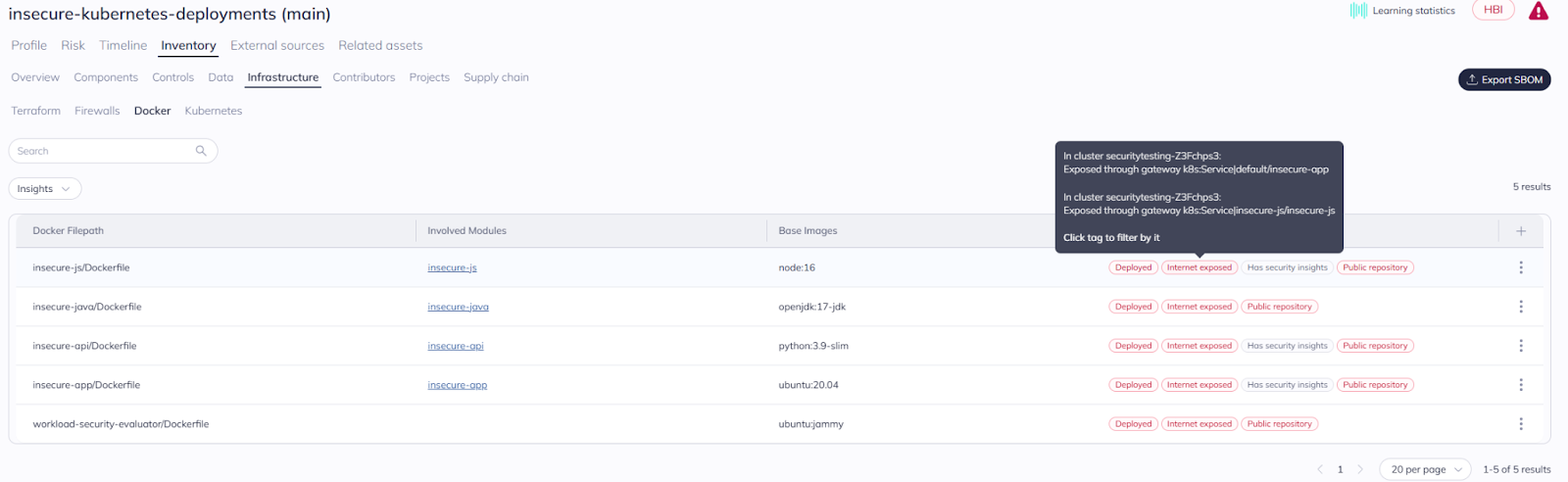
From an infrastructure perspective, code to cloud means tracing a piece of code as it’s built onto a container image, and deployed on a container orchestration platform. This type of code to cloud is especially helpful for diagnosing container and IaC findings, as it ties the deployed infrastructure vulnerabilities back to their point of origin.
“Code to API” Correlation
From an application perspective however, there’s a type of code to cloud that’s defined by correlating APIs and their traffic back to their originating code:

This kind of code to cloud picture is much more helpful for prioritizing SAST findings, as it tells you how data flows actually happen in your infrastructure. Whereas the infrastructure code to cloud might be thought of as more “container to Kubernetes;” this code to cloud is more “Code to API Gateway.”
Combining the “Container to Orchestrator” and “Code to API” data is at the heart of why ASPMs need to exist - these technologies unfortunately evolved separately. Historically, these have been three distinct technologies: SAST + SCA providers, CNAPP (IaC + Container), and API Security (DAST + WAF). Only ASPMs seek to combine all of these data points into a single story that makes developer security happen.

Combining this data allows you to do some powerful filtering - like seeing exactly how internet traffic hits the relevant workloads. Not just seeing “oh wow, this pod gets traffic from the internet” but more specifically “how are these API’s accessed?” or “what repo or team should I go to in order to fix this API?”
Code to Cloud Methodologies
Now that we understand the different kinds of code to cloud and why they matter, we need to talk about different approaches that vendors have taken to solving this problem. These approaches create radically different user experiences and have big implications for what’s possible.
These approaches are:
Manual linking
Container Tagging
Data Modelling
1. Manual Linking
Some providers create a simple UI for manually matching up container images to their source repos. This is not a bad approach for smaller environments, where new services aren’t getting deployed constantly, and part of the new service checklist is simply “add this container relationship in the security tool.” However, this approach fails to scale for a myriad of reasons, most importantly, developers don’t always know what their finished container looks like when it finishes building.
2. Container Tagging
This approach to code to cloud mapping is a funny sales hack, because it allows you to say you do automatic mapping, but with a giant manual intervention being needed to get it started. Typically, these providers try to sell container tagging as “image signing,” wherein you cryptographically authenticate that an image hasn’t been altered with - it’s signed by a private key only your build system has access to.
When you do this image signing, you’re able to add metadata into the signature such as what CI/CD runner built it, and what the name of the working repository is. This allows the image signing to work as a faux “code to cloud generator” under standard operating conditions. The problem with this approach is that most people don’t work under standard operating conditions!
I consider this approach a neat trick more than a true solution because it has numerous edge cases, and creates friction by forcing DevOps changes in order to get a security team benefit. The main thing to watch out for is that from a demo perspective, these providers can look like they’re doing the same thing as the below category.
3. Data Modelling
The final approach is the holy grail of code to cloud - it relies on data modelling to create code to cloud associations. At its core, this looks at some combination of artifacts generated statically, such as file names or contents, and matches them to their runtime counterparts via either integrating with a runtime provider or providing a connector themselves.
The issue here is that a lot of providers don’t have enough data to make this approach work at scale. If a provider has built scanning first, rather than a broader source code management tracking system, it can be quite difficult to pile up enough metadata to stick some kind of AI on it and figure out the correct associations. For example, many vulnerability management tools can be crippled by the data they ingest from - many vulnerability scanners don’t provide enough context to help create a code to cloud mapping.
I can say that Apiiro was one of the few tools I’ve used that takes this approach where I hooked everything up and it “just worked.” (But as a disclaimer, I haven’t used all of them, and this is a small environment). I added my Github repository and my Kubernetes cluster, and all the associations happened by themselves. I suspect that it’s due to the amount of data Apiiro tracks about source code itself - from material changes, to “code modules” to API endpoints - because they were already generating runtime models of what the code should look like, they’re really just comparing those models to the real thing. This is what Apiiro calls their Deep Code Analysis (DCA) capabilities, and it’s been at the heart of the platform since the beginning.
True Contextualization

The outcome of taking a data modeling approach is that it best reflects how real world prioritization works - a combination of development and runtime questions need to be asked in order to prioritize a vulnerability.
On the developer (left) side:
What business function does this code serve?
Is it under active development or will we need to pull new developers onto the project?
Where in our application architecture does this repository sit?
On the runtime (right) side:
Is this code accessible from the internet?
Where is it deployed, what data does that environment have access to?
What data is being processed by the application?
By tying together “Container to Orchestration” and “Code to API” visibility, teams are able to more effectively triage, assign, and ultimately remediate their vulnerabilities. This is why “Code to Runtime” capabilities have become a non-negotiable in ASPM tooling.
I love reading your articles and wish to be a paid subscriber. Nothing comes for free and i can see you are putting in lot of effort and research to get these articles. However, can you please consider membership fee for international audience? I am in India and want to buy your annual membership plan, but $1000 is quite a bit for a 24Y old who just got graduated.