

WTF is Cloud Detection and Response (CDR)?
Let me cook, we're making the future here! Part 1/3.


I first saw Sysdig back in 2021. At that time, I had used a different CSPM for 2 years, and was completely disenchanted with calling CSPM “cloud security.” My CSPM was an ignored dashboard of useless alerts ranging from mildly interesting to wildly unimportant. All the while, my developers were strapping together the wild west of application development in Kubernetes, with 99%+ of their actions going entirely undetected by CSPM.
I’m talking about developers letting us know they’re doing something they think is going to trigger an alert, but the alert never comes, sound familiar?
When I ran an evaluation of cloud security tools, I was floored at how bad they were at detecting Kubernetes events, especially at runtime. Only Sysdig and DataDog performed admirably, detecting about half of the events that I would’ve liked them to. These tools offered me a glimmer of hope for the future of real cloud security, but the problem was that, as an industry, we were simply ignoring Kubernetes. With the recent increase in posting about CDR and Kubernetes, it’s my hope that the reality of cloud environments has finally begun to take hold with security teams.
In this post we’ll talk about the heart of cloud security, why CNAPP misses it, and why the future gets me so excited. While Forrester might argue that CDR doesn’t exist, I think they’re making two mistakes:
They’re making the “cloud” too broad
They’re not aware of the small but mighty vendors making CDR a reality.
What is Detection & Response?

At it’s heart, detection and response tools take in logs, and take actions based on where they’re deployed and what they’re seeing. Tools like Darktrace detect and respond based on network logs. SentinelOne looks at endpoint logs. XDR (eXtended Detection & Response) was an attempt to say “we’re looking at multiple sources at once and taking an action” but the technology has never managed to pass the gimmick stage. Ironically, XDR is very similar to CNAPP, where I strongly agree with what Forrester has to say!
Like CNAPP, XDR expanded to so many log ingestion points that it never really succeeded at putting enough meaningful use cases together. The idea of tracing a malicious email, to a downloaded file, to network calls across the network, to a server download, to an outbound connection, (and the story continues) sounds really promising - but at the end of the day the simplicity of an EDR proves much more realistic: just quarantine the malicious file.
While product managers had ideas of what they wanted to sell, detection & SOAR engineers could never quite make it work - taking autonomous response actions across multiple endpoints based on multiple cross-tool logs.
So What is CDR?
The main problem continues to be the wildly different maturity of organizations at using eBPF. This article from AccuKnox does a tremendous job at showing the complexity of different approaches to Kubernetes security in terms of the speed of sending a response. This is not an easy challenge, which is why even though there are a million providers out there with “an eBPF agent” - the maturity and even overall approaches of using the agent is wildly different between vendors. As an example, the approaches of Rad and Sysdig differ significantly from one another (full video on eBPF here).
I agree with Forrester that cloud detection & response encompasses bringing together several different log sources, but I disagree that it’s really as complex as they suggest. Defining CDR in the context of CNAPPs is impossible - these tools have horizontally expanded to meet every wild enterprise cloud environment, missing the common core that drive actual applications. Far from being a feature of so many different tools, CDR is just tying eBPF and cloud logs into a meaningful exploit story for Kubernetes workloads. Let me explain.

First, since the cloud is just a datacenter with an API, we have to be willing to make some concessions when we talk about tooling and what it works on. Here are some examples:
Agentless scanning is wonderful until you’re using workloads without EBS volumes
eBPF agents are awesome until you’re using an unsupported OS
DSPM is super cool until it doesn’t support your groundbreaking NoSQL flavor
Library implementations work until you deploy no code solutions
Instead of worrying about every edge case, let’s make some generalizations about cloud architectures:
With that in mind, here’s the core of my argument for what CDR is - Cloud Detection and Response ties together logs from the Kubernetes Control Plane, Containers, and Cloud events into a single timeline for analysts along with response and remediation actions.
Defining CDR
Forrester suggests this for the definition of CDR:
The detection of and response to cyberattacks on detection surfaces in the cloud control plane, data plane, and management plane. This includes one or more cloud-native tools that prioritize security analyst experience for high-quality detection, complete investigation, and fast and effective response to cloud attacks.
For some editorial context, I didn’t pay for the full Forrester report, so I’m very open to criticism or response on something I may have missed from their analysis.
I’m generally okay with the Forrester definition, but it interprets the cloud by its messy possibilities instead of the most commonly deployed architectures. Their separation of planes can better be reduced to cloud identities and cloud workloads; Forrester includes the “management plane” (like Office 365 logs) - but I don’t think it’s necessary to expand into SaaS more broadly. Correlating these logs can be helpful, like Sysdig’s example here, but I don’t think this is necessary for CDR. I’m going to ignore cloud identities for now, because I think the solution here is actually the expansion of JIT access (like Axiom and P0), boundaries (like Sonrai and InstaSecure) and further consolidation into identity federation - these approaches need to develop more before “detection and response” can come to fruition. Frankly, with identities, it’s hard to detect malicious activity when we’re still not sure what we want to see.
I went to Gartner for a definition to compare with, but theirs is vague without meaning, “to automate the investigation and collection of digital forensics in the cloud”…okay, super helpful.
Instead of these, I’d suggest:
Cloud Detection and Response tools detect malicious activities in common cloud workloads (containers & Kubernetes) and contextualizes them with other cloud services to create a single attack path across cloud environments.
To me, this is what cloud security has really meant all along - responding to cloud attacks. Instead, CNAPP led us down the road of cloud security = endless scanning. Additionally, existing EDR have expanded just enough into cloud workloads to be able to say they support them, but with little actual insight.
Examples of CDRs
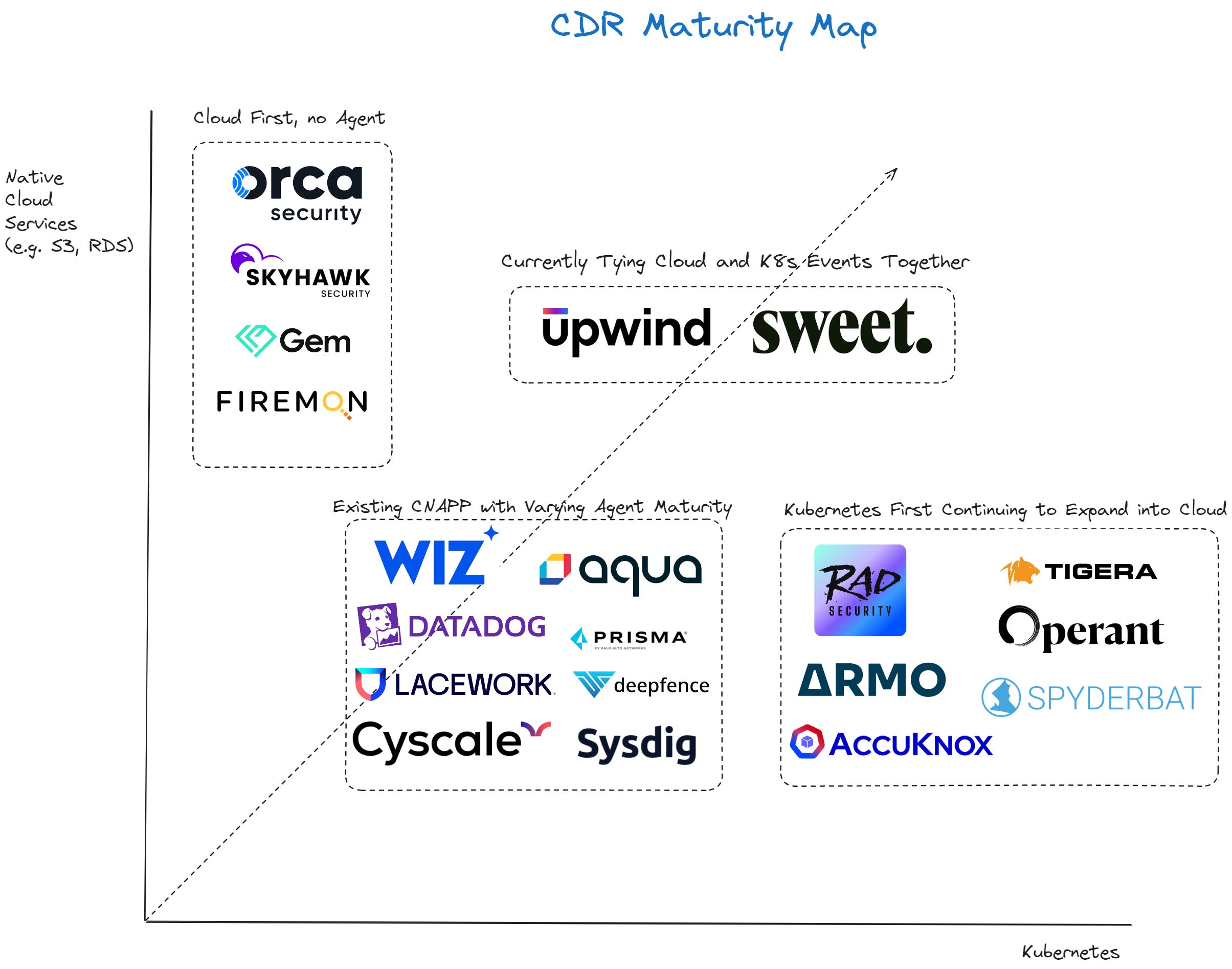
Alright, let me explain this image. I haven’t (yet) done hands on evaluations across all of these tools, so I’m not commenting on the maturity of any particular functionality. Instead, I’m bundling these tools based on a combination of demoes, hands on time, log ingestion points, and their marketing material. Here are the examples of correlating cloud with container events, with the relevant parts circled in red:

Here are two examples of what I think is the closest alternative, but not quite what I’m talking about from Sysdig and RAD:


The above images shows why this gets confusing in the CNAPP realm - almost every CNAPP can tell you theoretically what cloud resources a host can access, but only CDR will tell you what it is accessing - especially during an attack. Additionally, maturity in addressing Kubernetes contexts varies wildly.
The focus from Upwind and Sweet is showing real time traffic between containers and cloud resources, data that is indispensable to investigating real world attacks. The alternative is just some process ran some commands.
What Attack are we Stopping?
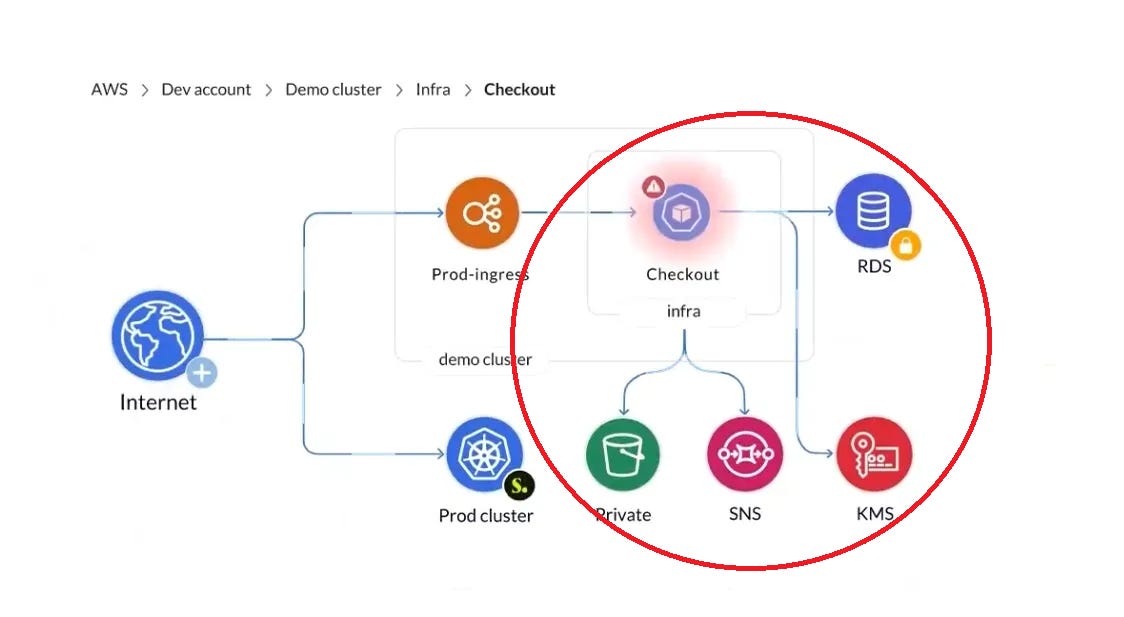
Here’s why tying together this context matters. A lot of companies talk about “internet reachability” as though it’s a simple prioritization method, but look at this super common architecture:

At this point, there are some tools that can draw this diagram with varying degrees of success; however, let’s say an attack has discovered a vulnerability with the way our Email Service parses email messages from the Kafka broker, which is AWS Managed Kafka (MSK). They publish a malicious string through the order service, it gets written to the broker and then consumed by the email service, which then gives them a foothold into your infrastructure.
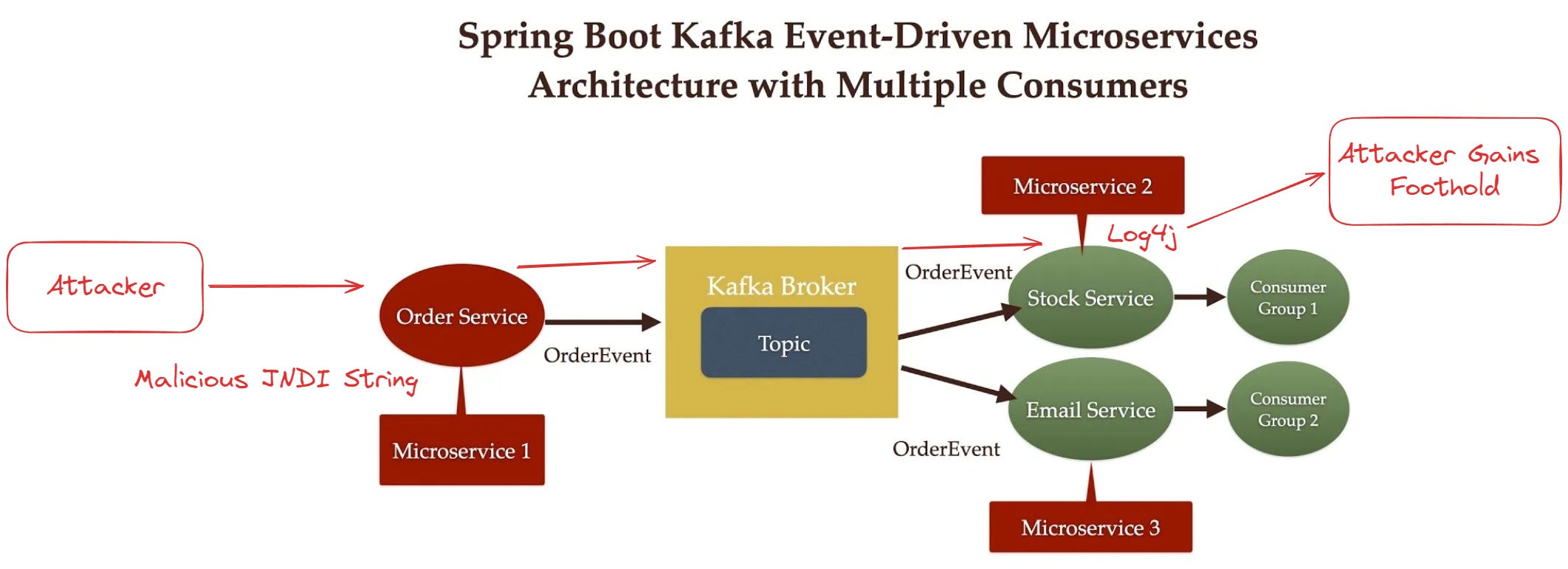
Let me start by saying that I like modern Kubernetes security tools even without cloud context, because they give you an option to respond. If Log4J spawns a shell which starts exploring around, I could talk all day about each vendor in the Kubernetes box and how they may or may not detect each action based on the specific things the attacker did.
Where Upwind and Sweet differ from this is being able to tell me the more full story of how the attacker got there, where the exploit is coming from, and where the attacker went in my full environment. Not just where they could’ve gone, but where they did go.
Let’s say I’m using Sysdig and it tells me something funky has happened with this container, specifically that the web process has spawned a shell. After killing the container, I’m going to need to dig into the application logs around that time to try and figure out how the attacker is getting into the system - the pod forensics by themselves will only tell me so much.
Instead, a CDR provider should tie that story together: we’re seeing malicious looking Kafka messages getting written as the consumer is getting popped, so you can know they’re probably related. Similar examples would be an attacker changing cloud DB settings to allow them to access it from another network, an attacker exfiltrating S3 data, or adding a new lambda function to allow them to silently listen to data.

At it’s core, CDR recognizes that modern applications are built on Kubernetes and cloud native services, and that both are intrinsically related to how real world attacks might happen. Yes there are a lot of edge cases, but the Kubernetes to cloud service and back again storyline is the heart of CDR, and it’s what makes Cloud Detection and Response actually possible.
Where we’re going
Next week, we’ll tackle ADR, because ADR has some unique things it can do in this scenario as well, that overlap. The week after, I won’t spoil it, but we’re going to create a new category, truly every analyst’s dream - and the best part, no one’s doing it yet.
In case you missed it:
I went full time! I thought that would mean more time for Latio, but to be honest it’s just meant more stuff! Here’s the about page and our advisory board!
I was at Reinforce last week and got to meet some legendary friends in the industry and get the usual dose of vendor pitches - runtime’s definitely back.
Big Latio List update this week as I finally caught up from the last month, full changelog here.
James,
I find your posts very interesting and helpful. Thanks. At Sysdig, we do correlate live cloud events (and not just cloud posture findings) to container events. We extract live detections from cloud audit logs, Okta logs and so on, and a lot of our energy is in correlating across cloud control plane events, identity behavioral events (in the cloud) and workload events. Would love to share what we do as and when it makes sense.