

WTF is Cloud Application Detection Response (CADR)?
Everything security teams need to detect real time attacks against modern infrastructure (Part 3/3)


“Please, we want one more acronym!” I can hear the legions of cybersecurity professionals screaming from their operations centers. The world of cybersecurity is already flooded with acronyms, but in this article, I’ll be arguing that there will be a future consolidation of the following ones into a single technology:
Application Detection Response (ADR)
Cloud Detection Response (CDR)
Kubernetes Detection Response (KDR)
Cloud Workload Protection Platform (CWPP)
Cloud Native Application Protection Platform (CNAPP) - The runtime half of it
Continuous Threat Exposure Management (CTEM)
API Security (the runtime kind, e.g. NoName and Salt)
I’m suggesting we call this new technology Cloud Application Detection Response (CADR), and that it be considered everything you need to detect & respond to attacks on your cloud hosted applications. It does this by combining three types of logs:
Cloud management logs (e.g. Cloudtrail, Cloudwatch, and KubeAPI)
Container workload logs (e.g. eBPF)
Application layer logs (e.g. Open Telemetry, network, and other instrumentation)
Into a single storyline with tools for Security Operations Teams to detect and respond to modern threats on cloud workloads.
In short, it’s all about being able to draw this graph:
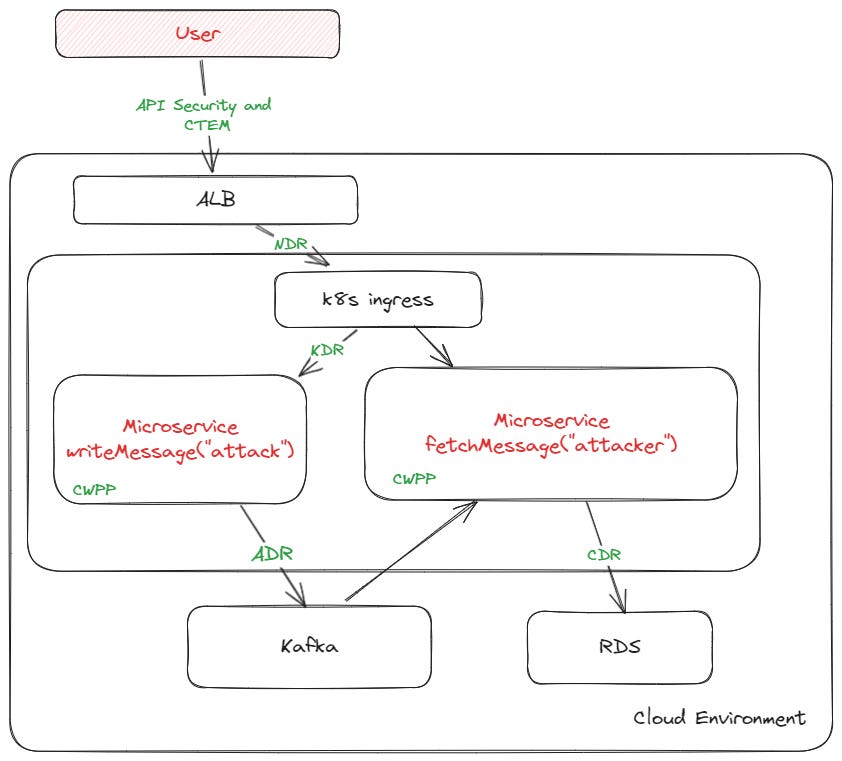
Each of the acronyms above can draw various pieces of this attack but, despite having access to the same logs, no one can quite put the whole picture together.
In this article, we’ll talk about why this category will emerge, give a couple examples about why it matters, before concluding with the go to market challenges.
Why CADR?
James, do we really need another acronym? Cybersecurity professionals get frustrated with acronyms because they’re usually thinly veiled marketing ploys to repackage an existing technology as “revolutionary.” For example, CTEM and ASM do very little besides be a feature of good CSPMs. I’m arguing for CADR not because I’m trying to pump up the valuation of a bunch of dying products, but because it solves a real problem facing SOCs: securing applications and critical infrastructure.
CADR solves problems I’ve experienced for years on the front lines - from working with a SOC to working with developers - runtime application alerts are full of false positives, don’t provide enough context to understand what happened, and almost always need to be escalated to a DevOps team. As an early adopter of Kubernetes (K8s) and trying to secure it, we’ve had to settle with big blind spots into nodes, pods, and the workloads running on them. It’s almost impossible to get enough information to accurately put together the complete story of the attack.
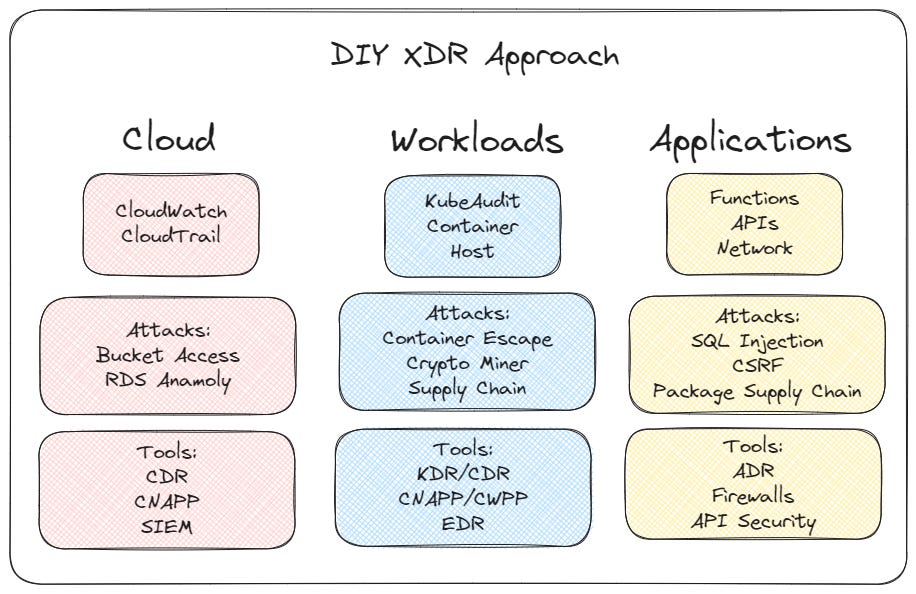
Current cloud detection response solutions are too siloed. Either they provide container level alerts, package alerts, network alerts, or application ones. Attacks go undiscovered because security teams are lucky to have even one tool deployed in their Kubernetes cluster, and that tool has a mixed chance to catch any real world attack depending on what the attacker does. While the “security has layers like an onion” defense certainly applies, the answer can’t be installing 5 different agents that are all better or worse at specific things across your entire stack. The only thing worse than 1 CrowdStrike agent taking down prod is 5 different ones.
Trying to build this response graph yourself would be a total nightmare, prohibitively expensive, and probably not even work. You have a few options, all of which are bad:
Ingest the logs directly into your SIEM - this will be prohibitively expensive when many companies already forsake VPC flow logs and similar monitoring logs due to cost. Cross log source correlation is also a well defined nightmare.
Ingest the alerts from points solutions into your SIEM - this is why attacks go undetected for so long, SOCs can’t put the entire story together because they don’t have adequate information. If I get a malicious pod created alert and just kill the pod, I’m missing the context to realize a broader attack is happening.
Segment your teams to each manage different tools - this is an extension of the previous issue, it relies on teams to manually collaborate across tools to put together attack chains..
Before we dive too deeply into the solutions, let’s take a step back and look at data on modern attacks.
What’s the Nature of Modern Attacks?
According to the 2024 Mandiant m-trends report, attackers are typically well established in environments with zero detection for a long period of time, and they’re often the ones notifying their victims rather than being caught. This is our first data point that some visibility is missing, attackers typically live in environments for a long time, and are often the ones who notify the victim that they’ve been successful.

Second, attackers typically exploit some vulnerability or misconfiguration, and then use that initial vector to laterally move in the environment. This information is nothing new to SOCs; however, in cloud security many have chosen to ignore detecting lateral movement and start from scratch by focusing on nagging developers over vulnerabilities that do nothing to detect or stop attacks in real time. At some point, cloud security got equated with vulnerability scanning instead of real defense.

To be clear, I’m not saying scanning for misconfigurations and vulnerabilities is bad. I am saying that it takes 10+ days to detect attackers in your environment (if at all), because there’s a lack of runtime visibility into cloud environments. If we have total visibility into “the cloud” with CNAPPs, why do we miss breaches for days at a time, or often altogether? Finally, let’s look at how malware gets onto endpoints:

Ultimately, attackers gain a foothold in workloads, not in “clouds.” So in order to do cloud security, it’s about time we get visibility into cloud workloads.
How do I detect these things?
Let’s create an example attack that fits in line with the Mandiant report. First, the most common vulnerabilities were seen from popular “in the news” vendor exploits - like MOVEit or Oracle Web Applications. Part of the increase in Kubernetes deployments is vendor deployment adoptions as well: Atlassian and GitLab are two examples of commonly self hosted tools that have Kubernetes deployment options.
As an example attack, let’s pick a recent one from GitLab, CVE-2024-6385 from July 12th 2024. This attack allows the execution of code by an attacker triggering a pipeline as another user. No amount of posture management is going to detect that this happens - the best it can do is tell you you’re using a vulnerable GitLab version.

Most of these severe “in the news” kind of CVE exploits work in exactly the same way. The attacker is able to inject code into your production systems and exfil data. In fact, I chose this as just the latest critical vulnerability, but they all follow this same general pattern:
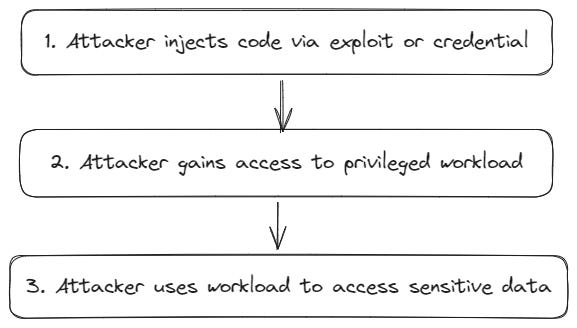
The attack chain hasn’t changed, it’s just gotten a lot more complicated in the cloud. The old architecture only needed a WAF and EDR, unfortunately many security teams are stuck in this way of thinking.

Let’s return to the real world example - your DevOps team is scrambling to patch your GitLab, and you need to know if you’ve been exploited or not, and get protections in place to buy them time. If you only have a WAF or an EDR, your response options are dead in the water - which is where many security teams find themselves with new exploits.
Right now, you’d need separate tools to attempt different responses:
You might have a WAF or API Security tool in front of your GitLab instance to look for exploit attempts.
You might have a container runtime solutions that can look for malicious processes. But in this example, most wouldn’t spot it because runners are commonly excluded because the workloads are changing a lot by their nature.
An ADR or KDR could detect if the attacker tries to manipulate your actual application in order to fetch the sensitive data using its privileged access to RDS
Some CDRs or DSPM tools could see the queries that the attacker used to get to the RDS data
Some NDRs or CDRs would see the outbound connection to the attacker server.
This makes cloud investigation and response almost impossible for SOCs. There are simply too many detached tools to try and follow this attack path and look for an exploit. Furthermore, the details of every attack will make it so you’re flipping a coin if your existing solution is going to detect it.
Back to Basics
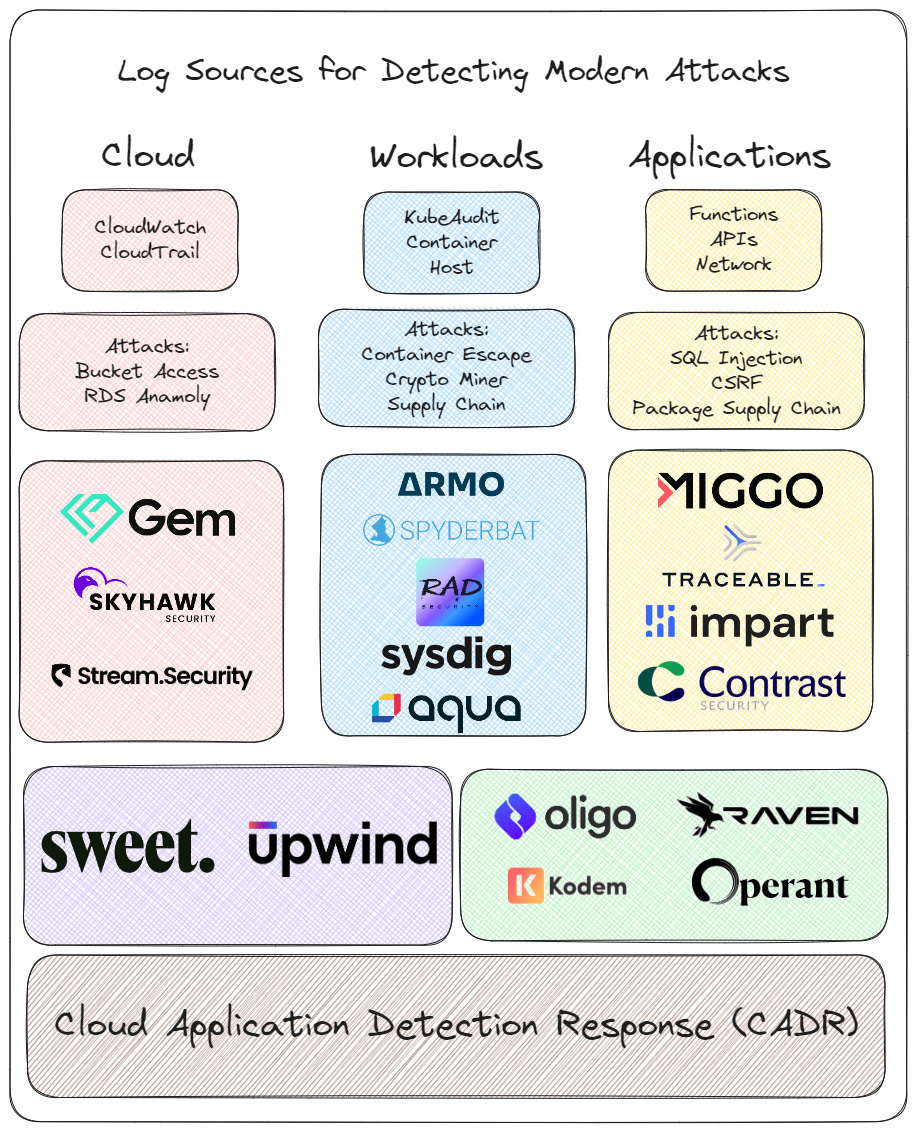
In order to reliably detect modern attacks, let’s think like a SOC and figure out what log sources we need. Most of these log sources are not ingested into SIEMs because they’re too verbose and expensive. Additionally, they require complex logic to try and tie them together, creating the opportunity for a new category. Whether you’re using a CNAPP, KDR, CDR, or the list goes on, none of these tools are doing the line by line log correlation needed to put together the full attack picture.
Each of these technologies provides needed insights to detecting modern attacks, that flow from applications, to containers, to cloud resources. These data flows lie at the heart of modern detection response, and are essential to building modern solutions.
While we might try to leave these providers in separate categories, the reality is that they already have the same install processes, and therefore access to the same data. This is why I view the convergence of all of these providers into a new tool that finally empowers SOCs to respond to modern cloud threats.
Why the Convergence?
First, each of these providers benefits from the same install method: helm install. Each of these tools can be deployed with a simple command, where the hardest part is having authentication setup to your cloud environment. One important caveat here is the importance of ease of adoption into ArgoCD deployments, since that’s how most Kubernetes stuff gets deployed.
Second, no one is going to be willing to deploy multiple security agents across their thousands of nodes, and pay the price to do so. While the security nerd in me would love to have Oligo, Raven, Kodem, Operant, and Sweet all running next to each other for different benefits, these tools don’t play nicely together, and my CISO and DevOps teams would be racing to pull the plug on my ambitions.
Third, these tools are all majorly differentiated by being leaps and bounds ahead of traditional EDRs like CrowdStrike and SentinelOne, giving them an opportunity to displace these providers as runtime solutions. CrowdStrike has enough of a working container product to create confusion in the marketplace, so only a solution that stands out will be able to win over customers.
At the end of the day, the one who wins the market will:
Be easy to deploy with low overhead
Make the complex challenge of interpreting these log sources easy enough for people just getting started in the SOC
Automate safe quarantining actions that don’t break production
Surface runtime insights to also help with the vulnerability challenge
Create a UX that empowers SOC users instead of confusing them
Right now is truly the most exciting time to be building a product in this area. eBPF is far from well established, and every decision has massive performance, detection, and usability trade-offs. It is far from clear what methodology, from baselining to injecting into user space, is going to end up being the best. There will be some big winners and losers in this category over the next 5 years, and in many ways it reminds me of the early CSPM days as providers are committing to different methodologies.
Does the CrowdStrike Shutdown Change Anything?
The CrowdStrike meltdown this last weekend has certainly emphasized the need to trust security agents running in production. To put it simply, security agents need to be able to kill processes and delete files in order to stop attacks. This means there will always exist some risk to breaking production. However, here are 4 ways that these tools are much less risky to deploy and maintain than CrowdStrike and Windows.
The tools use eBPF, which is kernel safe, meaning at the least the entire OS won’t crash. The worst case scenario is your application breaking, not your servers. Read more about eBPF validation here.
The control plane is typically hosted in most deployments, meaning there’s no agent installed on it. This means you’re always just one helm uninstall away from fixing everything.
The testing and scaling options available to vendors in Kubernetes are much more robust, allowing them to stop actions based on things like seeing multiple pods or nodes going down in a given time period.
In a worst case scenario, however unlikely, re-deploying an entire Kubernetes cluster is (usually) much simpler than re-deploying and entire manually configured fleet of Windows servers. As long as you give your team time to get everything wired up with IaC.
Conclusion
Let’s return to the GitLab exploit from earlier. In response to that specific attack, I think Sweet Security or Upwind would be the most likely to detect the majority of it. However, if I choose a slightly different vulnerability, such as XZ utils, then I’m switching my answer to Oligo or Raven in terms of likelihood. But the reality is that any of these tools have a fair shot of detecting it or the follow ups from it. Even within these categories, there are still differences upon differences - such as Kodem’s ADR working quite differently than Oligo’s or Raven’s. At the end of the day, security professionals are tired of having to decide which exploits they want to be protected against. I’m advocating for a new category because security professionals need to be freed from trying to weigh pros and cons by trusting one Kubernetes agent that can detect, empower, and block runtime threats.
These logs have never been more accessible thanks to new observability technologies like eBPF and Open Telemetry. We’re truly in the wild west of next generation runtime protection, where big early technological bets are going to pay off (or totally crash) in the long run! At some point in the coming weeks, I’ll address how these technologies also impact the future of vulnerability remediation with runtime insights.