

Building an AI Ready Vulnerability Management Program After NVD Changes and Claude Mythos
When AI discovery tools meet a slowing infrastructure

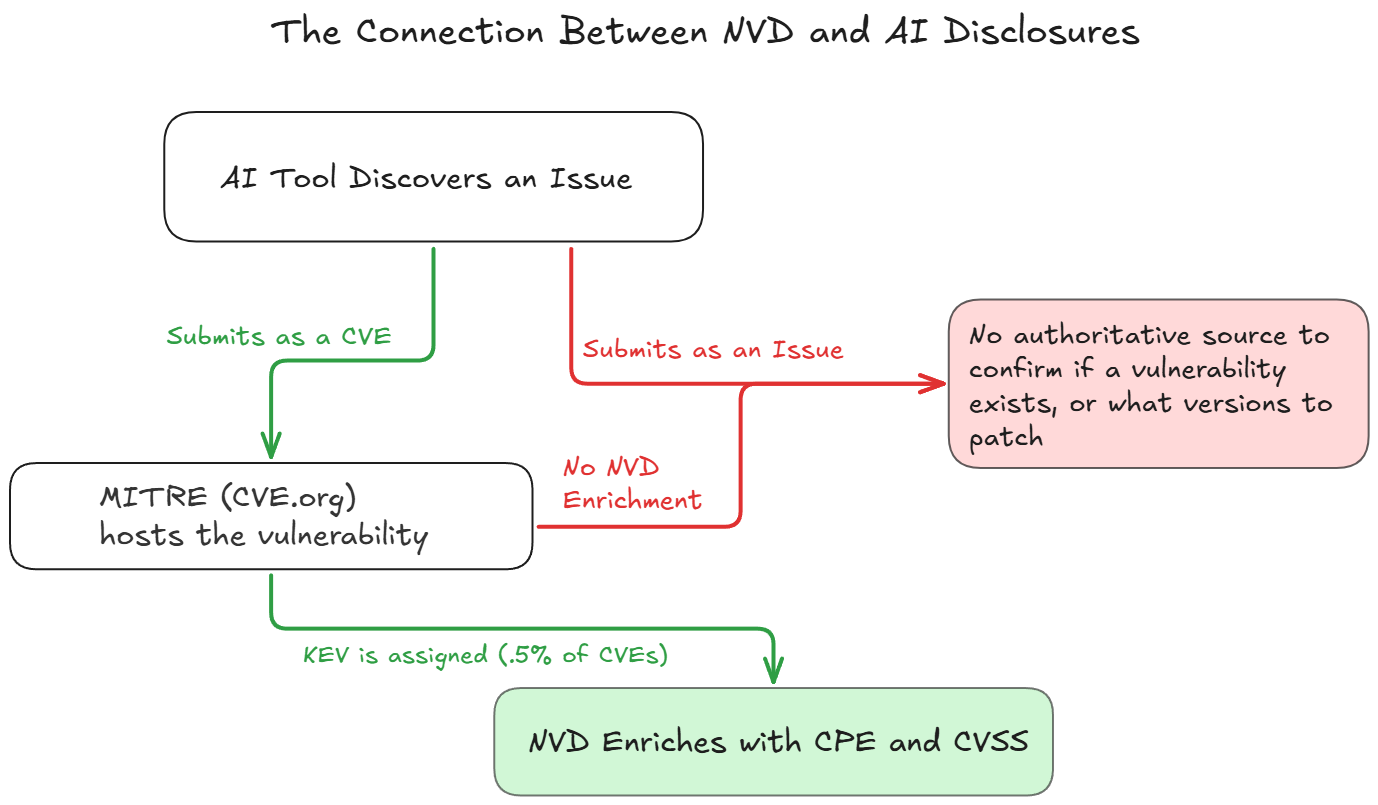
AI has increased attacker potential and Anthropic’s new release Mythos and vulnerability discovery has caused an industry panic. Mythos’ capabilities, and tools for deploying countermeasures are exciting; however, many teams don’t recognize that while vulnerability discovery is becoming more accessible than ever, the NVD ecosystem is falling further behind.
The NVD announced some large changes to their vulnerability enrichment program on April 15th, drastically reducing the scope of which vulnerabilities will receive enrichment. This announcement, compounded with the existing and expanding capabilities of AI researchers and attackers, means that the AI vulnerability problem is causing a crumbling foundation to deteriorate even faster.
This article explores what AI scanning tools mean for the future of vulnerability management, and what teams can do in the face of a collapsing Common Vulnerabilities and Exposures (CVE) ecosystem.
What is the NVD Changing and Why?
Historically, the National Vulnerability Database (NVD) would focus on every vulnerability submitted and is now pivoting to performing vulnerability enrichment for CVEs under the following conditions:
CVEs appearing in CISA’s Known Exploited Vulnerabilities (KEV) Catalog
CVEs for software used within the federal government
CVEs for critical software as defined by Executive Order 14028
Over the last two years the NVD has attempted to introduce alternatives like creating a vendor consortium to help manage their enrichment backlog, but recently stated this won’t be happening. The only thing that’s clear is that vulnerability disclosure counts are higher than ever, and the NVD will be reducing their scope.
Why Does Vulnerability Enrichment Matter?
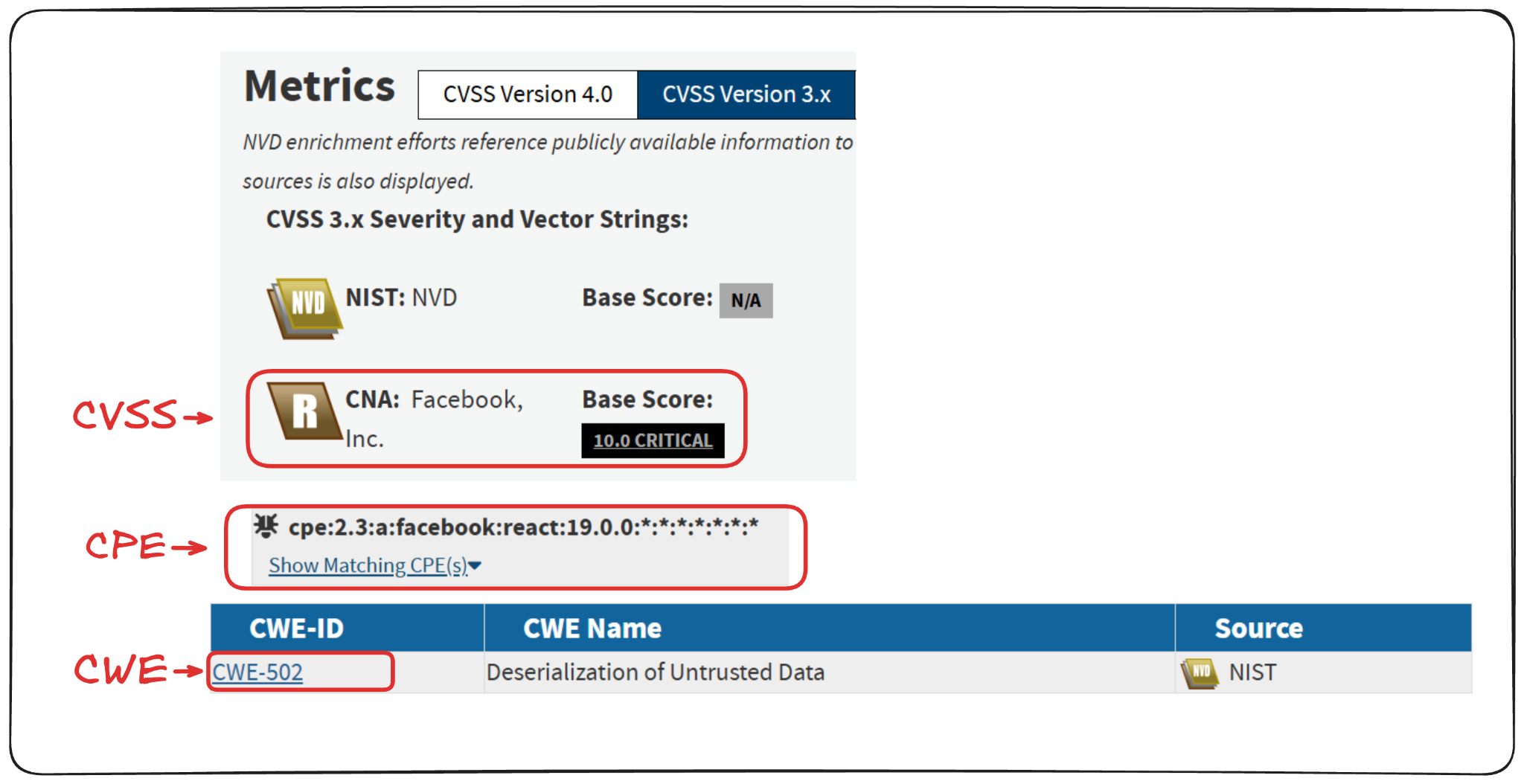
Vulnerability enrichment matters because they are the data points that make vulnerability findings actionable. Typically, vulnerabilities are submitted via a CVE Numbering Authority (CNA) (e.g. Adobe, Microsoft, Google) with a CVE ID (e.g. CVE-2025-55182), description, a Common Platform Enumeration (CPE) to identify the affected product (sometimes correctly formatted, oftentimes not), reference URLs, usually their own Common Vulnerability Scoring System (CVSS) with varying quality, and sometimes a Common Weakness Enumeration (CWE) (e.g. out of bounds write). These details are submitted by the CNA to CVE.org to inform security teams about vulnerabilities, before the NVD picks them up.
Once the NVD has the vulnerabilities, it enriches the data by standardizing the following information:
Adds a properly formatted CPE: This gives scanners the version ranges to flag for what’s impacted
Adds an authoritative CVSS: This is the primary prioritization tool of most organizations, even if contextual analysis, Exploit Prediction Scoring System (EPSS), KEV, and third party intelligence providers all add much more value
Adds a CWE: This allows researchers to correlate findings to attack vectors, and is important for long term security training prioritization
Groups reference URLs: This makes security responses faster
What are the Impacts of the NVD Changes?
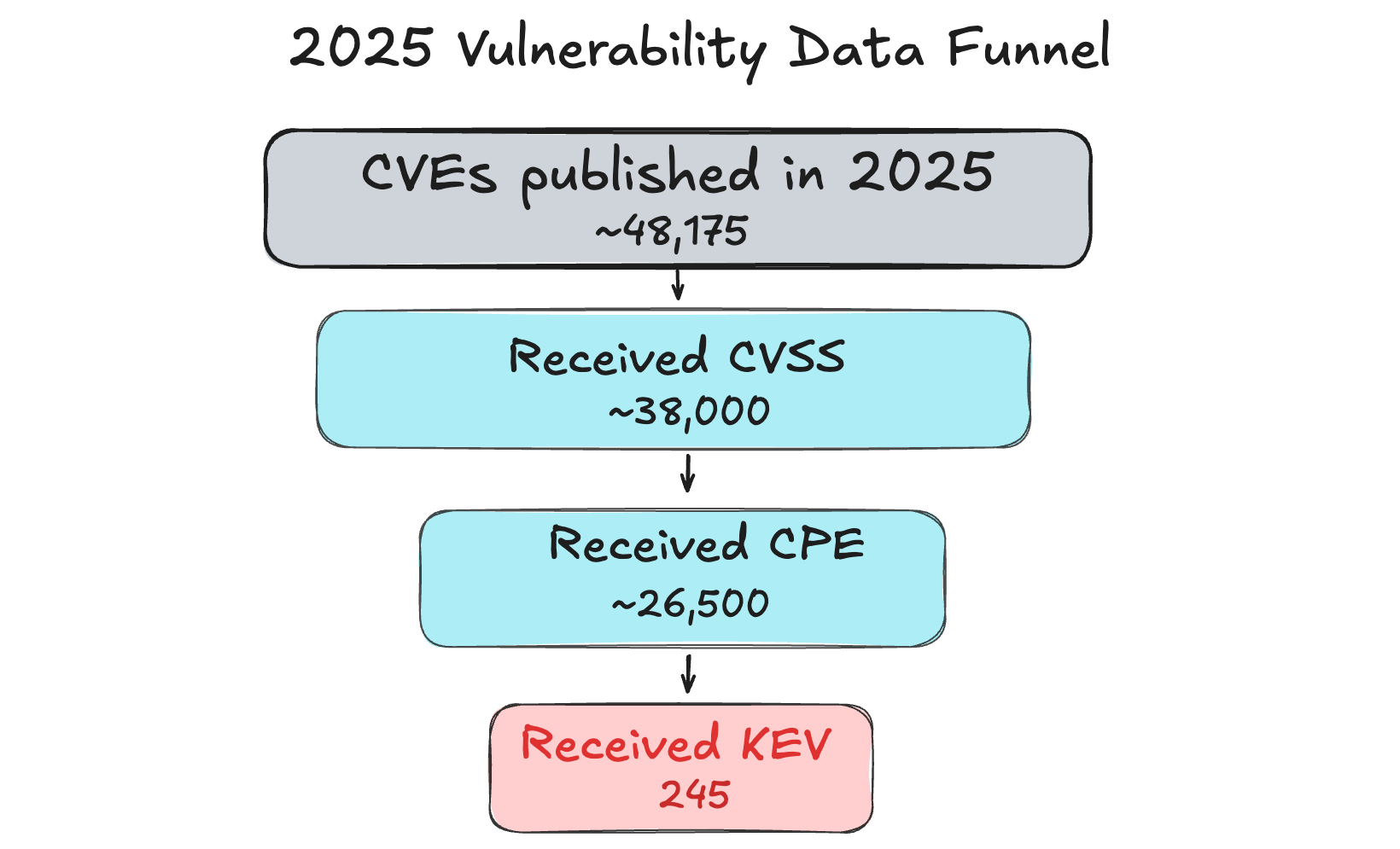
The TL;DR of the NVD changes is that they will only run enrichment on KEVs and critical software. The problem is that KEV has a few structural issues: the data is heavily informed by network and vendor specific data, what qualifies is extremely conservative, and only 0.5% of CVEs receive a KEV. What gets flagged as “exploited in the wild” tends to be what shows up in network telemetry - perimeter-facing CVEs in VPNs, firewalls, load balancers, file transfer appliances, and internet-exposed web apps. These are real vulnerabilities being exploited, but the selection bias is worth naming: KEV is a strong signal for what gets caught by the kinds of vendors used by the federal government, not necessarily for what’s actually being exploited most often.
Conversely, the dramatic rise in CVE disclosure, and the fear of putting Mythos into the wrong hands, comes primarily from analyzing open source software. This continues to be a growing concern - whether exploited through a web app pentester, a supply chain takeover, or otherwise, this is where the growing security case is growing. Unfortunately, this also seems to be the primary area NVD is distancing themselves from, meaning that Mythos is going to make this specific problem much worse. There is going to be a continuing explosion in CVEs in the area that is going to be evaluated with the least scrutiny.
What Do These Changes Mean for Security Programs?
For many security leaders, “shifting left” and “proactive security” has translated into CVE management. Many teams manage their vulnerability backlog based on CVSS alone, sometimes enriching with EPSS and KEV. This data provides the cornerstone of most vulnerability management programs, with teams relying on trustworthy data to reduce risk.
The CVE ecosystem is about to become even more fragmented in its usefulness, with vulnerability data becoming less consistent and maintainable. Teams will need to look outside of the NVD for enrichment, with third party vulnerability sources becoming more important. As a quick example, Flashpoint’s vulnerability database already tracks thousands of additional KEVs.
Access to AI tools like Claude Mythos has already caused an increase in vulnerability disclosures, and numerous major supply chain attacks. While Mythos has received all of the attention, several teams have recreated its results using older models with better scaffolding - Mythos is simply going to make these results more accessible. Teams building their vulnerability program on top of the CVE ecosystem are going to face major new risks without an ability to better prioritize, patch, and actively protect their systems.
How Teams Can Prepare
Security leaders must recognize that CVEs should not drive their security program, instead resorting to a combination of tools to consolidate and prioritize. Instead, teams should focus on:
On the proactive side, evolving your definition of vulnerability to include toxic combinations of misconfigurations and vulnerabilities - architectural decisions that make vulnerability exploitation more likely. This should be combined with having plans for making services as stateless as possible, so that continuous patching can become a reality. While “Agentic Patching” might sound nice - the patches will only be as resilient as your ability to deploy them to production safely. The reality is that a nightly rebuild of services fixes most vulnerabilities.
Additionally, deploying proactive guardrails and data boundaries will limit the attack surface of a breach. At a high level, this is a mindset shift from “what are my most critical vulnerabilities” to “how can I continuously patch and minimize my blast radius?” Utilize SCPs, data boundaries, and approved terraform modules to enforce cloud guardrails, shifting to an “assume breach” mindset.
On the runtime side, deploying meaningful runtime protection and visibility into your environment to catch application layer attacks and zero day exploits (CADR). Web application exploits were increasing even before these latest developments, and sophisticated attacks are quickly becoming easier to deploy with AI. The transition here is from process level detections with manual response windows to exploit blocking in real time.
Security Team’s Checklist for AI Vulnerability Readiness
Low Risk Environments
Do we have a basic inventory of what we’re running, including open-source dependencies, so a CVE without a CPE doesn’t leave us guessing?
Do we maintain asset and software inventories, and does our scanner flag CVEs even when NVD hasn’t enriched them yet?
Does our scanner use data besides NVD for enrichment? Is it from a trusted third party or in house?
Does our scanning tool maintain their own database of known vulnerabilities?
Medium Risk Environments
Are we prioritizing based on exploitability (KEV, EPSS, sensor telemetry, asset context) rather than raw CVSS? (Note: for more in-depth information on how to prioritize, see our article, How to do Vulnerability Prioritization).
Does our intel feed capture vulnerabilities that don’t yet have CVEs, or GitHub issues where a fix has landed before any advisory is published?
Are our services stateless enough that we can patch on a daily basis instead of scheduling disruptive patch windows?
Have we mapped toxic combinations of misconfigurations and vulnerabilities, not just individual CVEs?
Can we distinguish between “a CVE exists in this library” and “this code path is actually reachable in our app”?
How can we limit our exposure in the event of a breach, how are we minimizing our attack surface?
Do we have all of the application layer telemetry we need to detect and respond to an attack? Is it worth investing in better runtime detection (CADR)? (Note: for more information on supply chain telemetry, see our article on How to Know if you Were Impacted by Trivy).
High Risk Environments
Can we stop a zero-day exploit before it runs, or are we entirely dependent on patch cycles?
Do we have application layer runtime visibility (CADR) to detect exploitation of vulnerabilities that haven’t been disclosed yet?
Are we pulling from multiple KEV sources (CISA, Flashpoint FP KEV, VulnCheck KEV) rather than treating CISA KEV as the floor and the ceiling?
Should we be directly using a third-party vulnerability enrichment service (e.g. VulnCheck, Flashpoint) instead of relying on NVD or vendor data alone?
Do we have data boundaries and identity scoping in place so that a successful exploit doesn’t become a successful breach?
Can we patch internet-facing perimeter devices (VPNs, load balancers, file transfer appliances) within 24 hours of a KEV listing?
Can we rotate all of our NHI credentials within 24 hours?
Do we have coverage for exploited vulnerabilities that don’t have CVE IDs?
Do we have adequate threat intelligence for IoCs in order to threat hunt emerging exploits?
Do we have an incident response plan that assumes AI-accelerated exploitation timelines, not traditional ones?